
Batch Normalization 学习笔记
Batch Normaliza(BN)是现在几乎已经成为深度学习,特别是图像领域几乎标配的一种 Technique,常常能在论文中见到。拜读了 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift 这篇 Citation 3000+ 的论文和李宏毅老师的深度学习课程之后,写篇 Blog 作为学习笔记。
Motivation
Feature Scaling
李宏毅老师是以机器学习中常用的 Feature Scaling 来作为一开始的引入的,Feature Scaling 顾名思义,就是把各个特征的值通过计算数学期望和方差,进行一个放缩。
这个放缩有什么意义呢?如果我们的 Feature,如下图中的 X1 和 X2,其数值不在一个数量级上(1 vs 100),而如果他们对于最终结果的影响的权重是差不多的,则在我们的 Minimize Loss 的过程中,Loss 对 权重 W1 和 W2 的梯度有很大的差别,类似一个椭圆,这就会导致 Training 过程变得比较困难:因为如果要达到 Optima,我们在横/纵两个方向上要选择不同的 Learning Rate(横向较大,纵向较小),事实上这样的设置是比较困难,所以一般我们都会倾向于选择一个较小的 Learning Rate,这就导致了训练速度的下降。
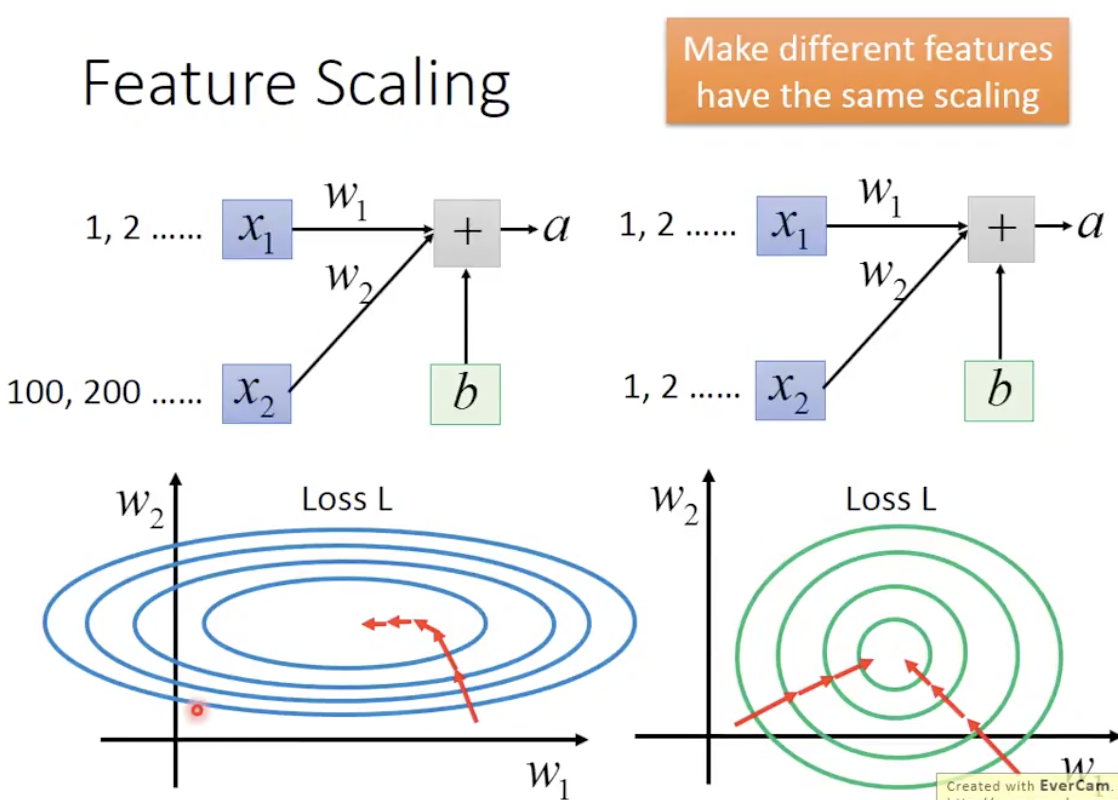
而经过放缩之后的梯度就比较接近一个正圆,各个方向上的梯度差不多,就能够使用较大的 Learning Rate,从而使得训练过程更快。
Internal Covariate Shift
Feature Scaling 是机器学习中的技巧,在深度学习,神经网络里,怎么去运用类似的方法呢?
Paper 作者在摘要里讲:深层神经网络复杂的一个原因是层之间的输入的分布随着训练而改变(参数发生变化),我的理解就是各层的输入可以看做是一个个的 Feature,而他们的数值不一并且随着时间变化。这一现象被作者成为 Internal Covariate Shift:
We define Internal Covariate Shift as the change in the distribution of network activations due to the change in network parameters during training.
这可能会导致训练中梯度消失(Gradient Saturation),造成训练困难,我们无可奈何地选择较小的 Learning Rate 以及精心设置的参数初始值以避免这种情况出现。
这个层之间输入的随训练变化而变化的过程,李宏毅老师的示意图非常形象:
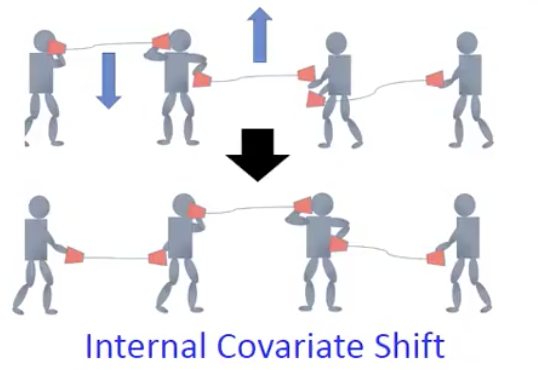
模型层与层之间的输入关系就好比一个音筒纸杯传话,彼此要对上才能达到目标。后面的人看前面的人旧的位置进行调整,而这个调整因为前面的人的自我调整导致不匹配(移动过多),因为需要不断地进行重复调整,导致这个过程非常缓慢。
解决的思路其实已经说了,就是要让输入在训练过程中保持一致,自然就想到用和 Feature Scaling 类似的手段,对这些层之间的 activations 做标准化的处理,但我们怎么得到同样随训练而变化的 mean 和 variance 呢?Batch Normalization 就是 Paper 作者提出的解决方法。
Algorithm
Batch Normalization 的思路也很简单,给每一个 Batch,计算一个 mean 和 variance,对每一个 Batch 中层之间的输入进行 Scaling 的操作:
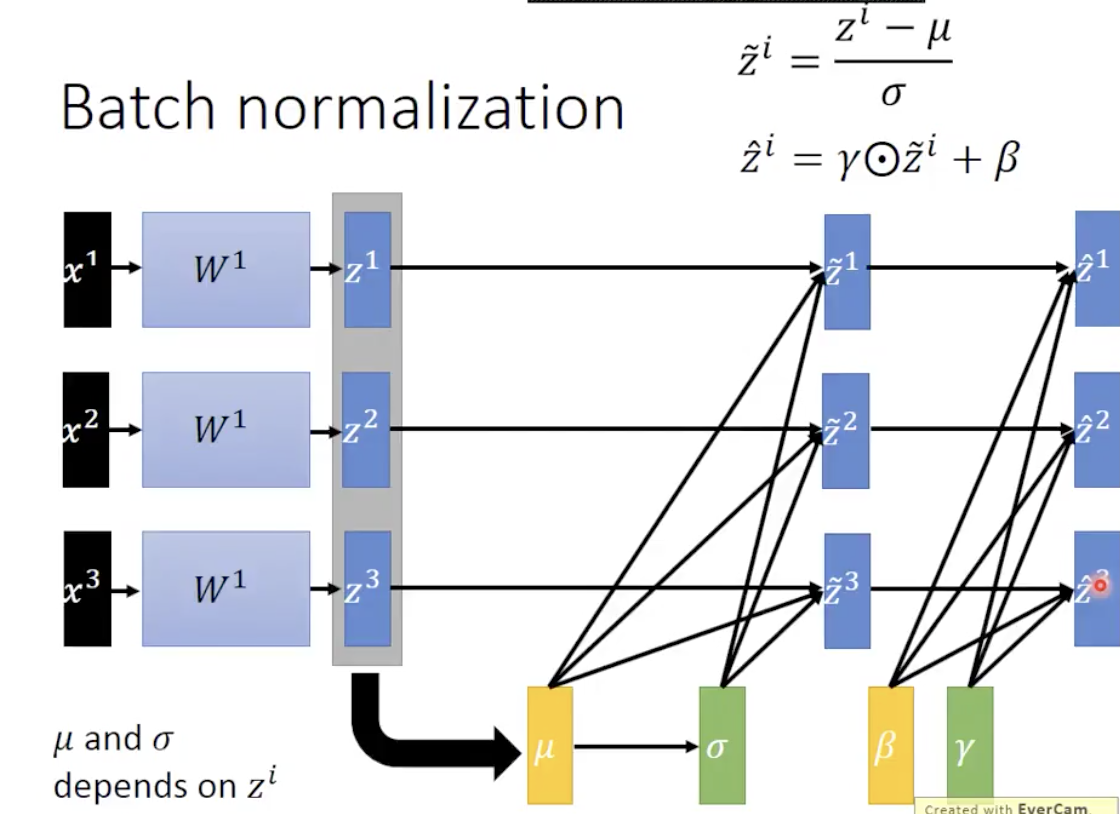
值得注意的是:是在 Z 上做 Scaling 操作,而不是经过激活函数之后得到的 A,事实上在 A 上做 Scaling 也是可以,但因为通过 Sigmoid 之类的激活函数之后再算梯度可能会出现 Saturation,这是我们不想要的,所以直接在 Z 上做可能会比较好。
同时在 Paper 中,还有两个参数 γ 和 β 用来对 normalize 之后的 x 进行一个放缩,这两个参数是相当于给模型一个自我调整 normalize 的旋钮,如果学出来 γ 等于 σ,β 等于 μ,就意味着可能我们的模型不需要 normalization,这个选择的权利交给神经网络自己。
因为 mean 和 variance 是在 batch 中计算的,这对 batch size 就提出了一定要求,不能太小,否则这个 mean 和 variance 就没有什么意义,Paper 中的算法如下:

Gradients
还有一点值得注意的是,在我们计算梯度的时候,μ 和 σ 事实上是对梯度有影响的,而不是一个常量。我们可以把 μ 和 σ 看做是一个 batch 的一个 feature,然后对其使用链式法则计算导数:
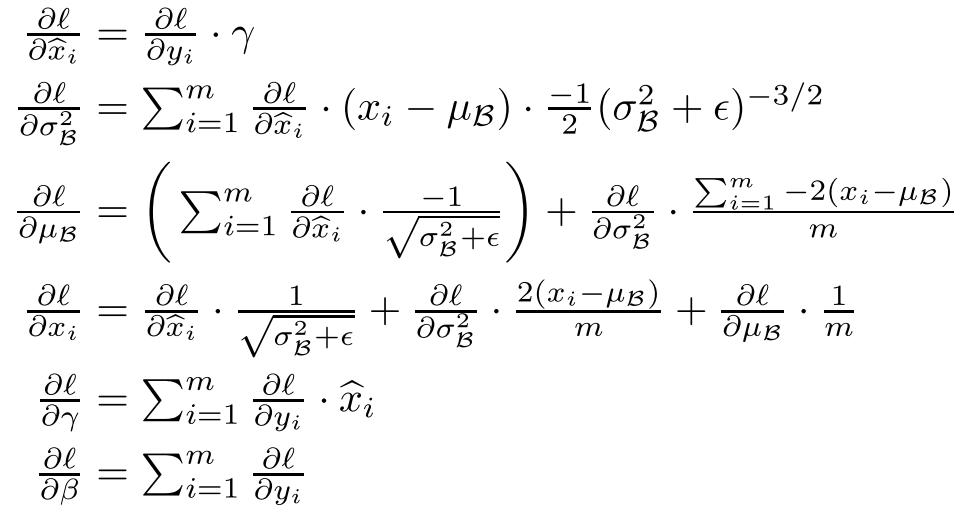
对于导数中的求和符号我是这么理解的:Loss Function 是一个 batch 中各个 example 的 loss 之和,因而其导数也是对各个 example 求导后相加得到。
Test
还有一个小细节,在我们 Test 的时候,μ 和 σ 怎么得到?其实也很简单,在训练过程中记录下每个 Batch 的 mean 和 variance,Test 的时候取平均就行。
Benifits
Batch Normalization 带来的好处有以下几点:
- 更大的 Learning Rate,意味着更快的训练速度
- 避免了一些 Gradient Vanishing/Exploding 的情况
- 降低了对 Initialization 的要求
- 能够起到一定的 Regularization 作用,可以去除 Dropout 和使用更小的 L2 罚项。
前面三点都是因为减轻了 Internal Covariate Shift 带来的好处,而第四点,Overfitting 实质上是 traning data 中的 noise 导致,通过 Normalization 我们可以消除这个 nosie,从而起到一定的 Regularization 作用。