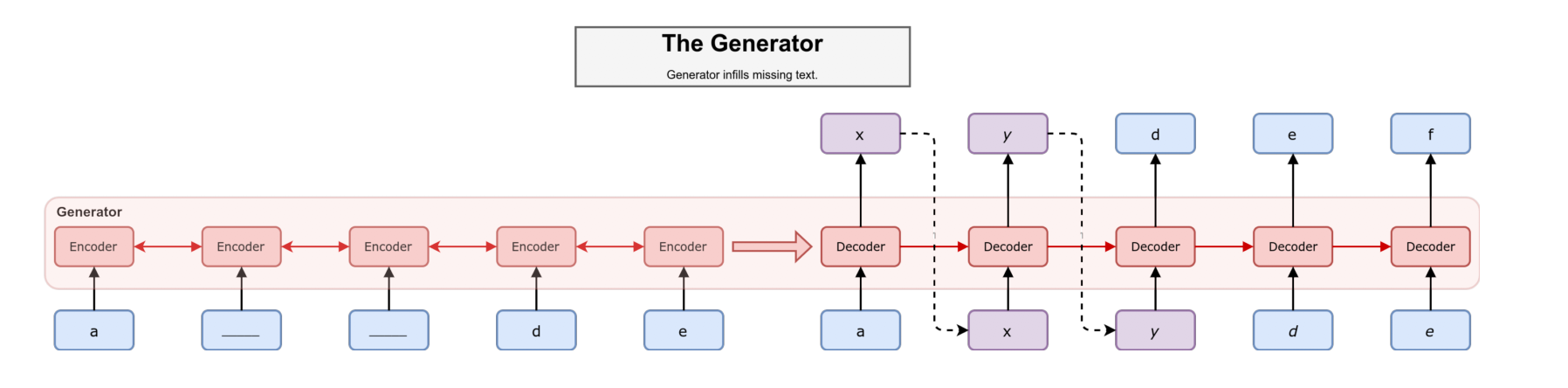
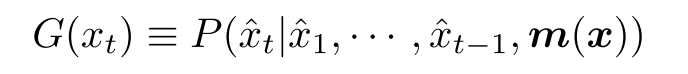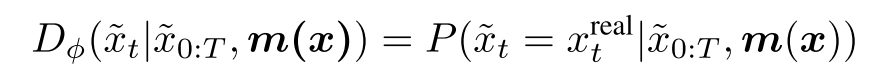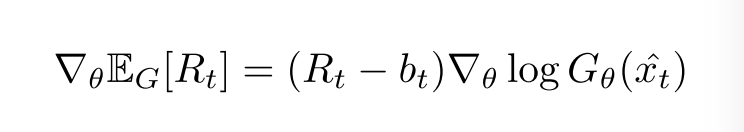上一篇讲 SeqGAN 的时候我们提到,SeqGAN 开创了 GAN 在 Text Generation 的先河,但是,实验结果证明,其 Idea 是能 Work(通过强化学习解决 GAN 无法在离散文本上梯度回传),合成数据中的 loss 确实有下降,但是在真实的古诗数据集上,其生成的文本质量不如人意。我利用全唐诗做了实验,不过囿于设备和时间原因,并没有充分的训练和调优,摘录部分生成结果如下:
Discriminator 的架构也是采用的 Seq2Seq,只不过是 many2one,即最后生成的每个 token 为真的概率。除了有填好的句子做为输入以外,$m(x)$ 也作为 Discriminator 的输入,文章是这么解释这么做的原因的:对于一个生成的句子 the director director guided the series ,如果没有 $m(x)$ 的话,那么判别器无法分别到底前一个 director 是原文呢还是后一个是,因为句子有可能是 the *associate* director guided the series 或者是 the director *expertly* guided the series,因此是有必要给判别器关于原文的信息,从而做出更好的判断。生成器和判别器的公式如下:
Actor-Critic
前面的文章谈到了,AC 的做法相比 Policy Gradient,很大的区别就在是单步更新,以及用一个 NN 来拟合 Advantage Function 来指导生成器生成更加逼真的文本。MaskGAN 的单步reward $r_t$ 设置为了 log probablity,也就是:
def gen_encoder(hparams, inputs, targets_present, is_training, reuse=None):
# We will use the same variable from the decoder: get word embedding matrix
with tf.variable_scope('encoder', reuse=reuse):
def lstm_cell():
return tf.contrib.rnn.BasicLSTMCell() #...
attn_cell = lstm_cell
if is_training and hparams.gen_vd_keep_prob < 1:
def attn_cell():
# .. Add variational dropout on the cell
cell = tf.contrib.rnn.MultiRNNCell(
[attn_cell() for _ in range(hparams.gen_num_layers)],
state_is_tuple=True)
initial_state = cell.zero_state(FLAGS.batch_size, tf.float32)
# 进行 Mask 操作
real_inputs = inputs
masked_inputs = transform_input_with_is_missing_token(
inputs, targets_present)
with tf.variable_scope('rnn') as scope:
hidden_states = []
# Split the embedding into two parts so that we can load the PTB
# weights into one part of the Variable.
if not FLAGS.seq2seq_share_embedding:
embedding = tf.get_variable('embedding',
[FLAGS.vocab_size, hparams.gen_rnn_size])
missing_embedding = tf.get_variable('missing_embedding',
[1, hparams.gen_rnn_size])
embedding = tf.concat([embedding, missing_embedding], axis=0)
real_rnn_inputs = tf.nn.embedding_lookup(embedding, real_inputs)
masked_rnn_inputs = tf.nn.embedding_lookup(embedding, masked_inputs)
state = initial_state
def make_mask(keep_prob, units):
random_tensor = keep_prob
# 0. if [keep_prob, 1.0) and 1. if [1.0, 1.0 + keep_prob)
random_tensor += tf.random_uniform(
tf.stack([FLAGS.batch_size, 1, units]))
return tf.floor(random_tensor) / keep_prob
if is_training:
output_mask = make_mask(hparams.gen_vd_keep_prob, hparams.gen_rnn_size)
hidden_states, state = tf.nn.dynamic_rnn(
cell, masked_rnn_inputs, initial_state=state, scope=scope)
if is_training:
hidden_states *= output_mask
final_masked_state = state
# 在未 mask 的输入上再来一次 encode 操作
real_state = initial_state
_, real_state = tf.nn.dynamic_rnn(
cell, real_rnn_inputs, initial_state=real_state, scope=scope)
final_state = real_state
return (hidden_states, final_masked_state), initial_state, final_state
with tf.variable_scope('rnn') as vs:
predictions = []
rnn_inputs = tf.nn.embedding_lookup(embedding, sequence)
for t in xrange(FLAGS.sequence_length):
if t > 0:
tf.get_variable_scope().reuse_variables()
#
rnn_in = rnn_inputs[:, t]
rnn_out, state = cell_dis(rnn_in, state)
# Prediction is linear output for Discriminator.
pred = tf.contrib.layers.linear(rnn_out, 1, scope=vs)
predictions.append(pred)
def critic_seq2seq_vd_derivative(hparams, sequence, is_training, reuse=None):
sequence = tf.cast(sequence, tf.int32)
# parameter setting ...
# reuse decoder's variables
with tf.variable_scope(
'dis/decoder/rnn/multi_rnn_cell', reuse=True) as dis_scope:
def lstm_cell():
return tf.contrib.rnn.BasicLSTMCell(
hparams.dis_rnn_size,
forget_bias=0.0,
state_is_tuple=True,
reuse=True)
attn_cell = lstm_cell
if is_training and hparams.dis_vd_keep_prob < 1:
def attn_cell():
return variational_dropout.VariationalDropoutWrapper(
lstm_cell(), FLAGS.batch_size, hparams.dis_rnn_size,
hparams.dis_vd_keep_prob, hparams.dis_vd_keep_prob)
cell_critic = tf.contrib.rnn.MultiRNNCell(
[attn_cell() for _ in range(hparams.dis_num_layers)],
state_is_tuple=True)
with tf.variable_scope('critic', reuse=reuse):
state_dis = cell_critic.zero_state(FLAGS.batch_size, tf.float32)
def make_mask(keep_prob, units):
# ..
if is_training:
output_mask = make_mask(hparams.dis_vd_keep_prob, hparams.dis_rnn_size)
with tf.variable_scope('rnn') as vs:
values = []
rnn_inputs = tf.nn.embedding_lookup(embedding, sequence)
for t in xrange(FLAGS.sequence_length):
if t > 0:
tf.get_variable_scope().reuse_variables()
if t == 0:
rnn_in = tf.zeros_like(rnn_inputs[:, 0])
else:
rnn_in = rnn_inputs[:, t - 1]
rnn_out, state_dis = cell_critic(rnn_in, state_dis, scope=dis_scope)
if is_training:
rnn_out *= output_mask
# Prediction is linear output for Discriminator.
value = tf.contrib.layers.linear(rnn_out, 1, scope=vs)
values.append(value)
values = tf.stack(values, axis=1)
return tf.squeeze(values, axis=2)
和文中所说的 head of discriminator 一致,代码中 Critic 的实现就是前半部分的 Discriminator,并且复用了 Discriminator 的参数,最后输出也就是一个 scalar,每个 token 的奖励 value;
Objective Function
我一开始以为公式中的 $r_t$ 是要计算每个 time step 的,但论文中的注释中说:
The REINFORCE objective should only be on the tokens that were missing. Specifically, the final Generator reward should be based on the Discriminator predictions on missing tokens.
The log probaibilities should be only for missing tokens and the baseline should be calculated only on the missing tokens.