
概率图模型学习笔记
概率图模型(PGM)是很重要的一类模型,听闻很久以前的”概率图模型加边”和现在的”神经网络加层”是同样的地位,但随着 DL 的发展,PGM 已经有一些不吃香了。但我依旧觉得这个一个很重要的知识点,对于 NLP 而言,还有很多序列标注的问题的 sota 还是基于 CRF(条件随机场,概率图模型的一种)取得的,所以还是很有必要学习一下,并且和之前的一些知识给串起来看,会有更多的收获。这篇文章就我记录《统计学习方法》和《统计自然语言处理》两本书中相关章节的学习笔记。
概率图模型
| 概率图模型,就是在概率模型的基础之上,用基于图的方式来表示概率分布,其中,图中的节点表示变量,节点之间边表示相应的概率关系。例如,我们把分词任务用概率图模型建模,$S$ 是一个汉语句子,$X$ 是其切分出来的词序列,那么,分词过程就可以看成是推断使 $P(X | S) $ 最大的 $X$ 分布;而如果是词性标注任务,那么就是给定序列 $X$,寻找词性标签序列 $T$ 使得 $P(T | X)$ 最大。我们在做的还是建模概率模型,特别之处就是变量之间的关系由一张图来确定,而通过这张图,我们可以引入一些外部的不确定性知识。 |
书中对常用的概率图模型的演变过程做了一个梳理:
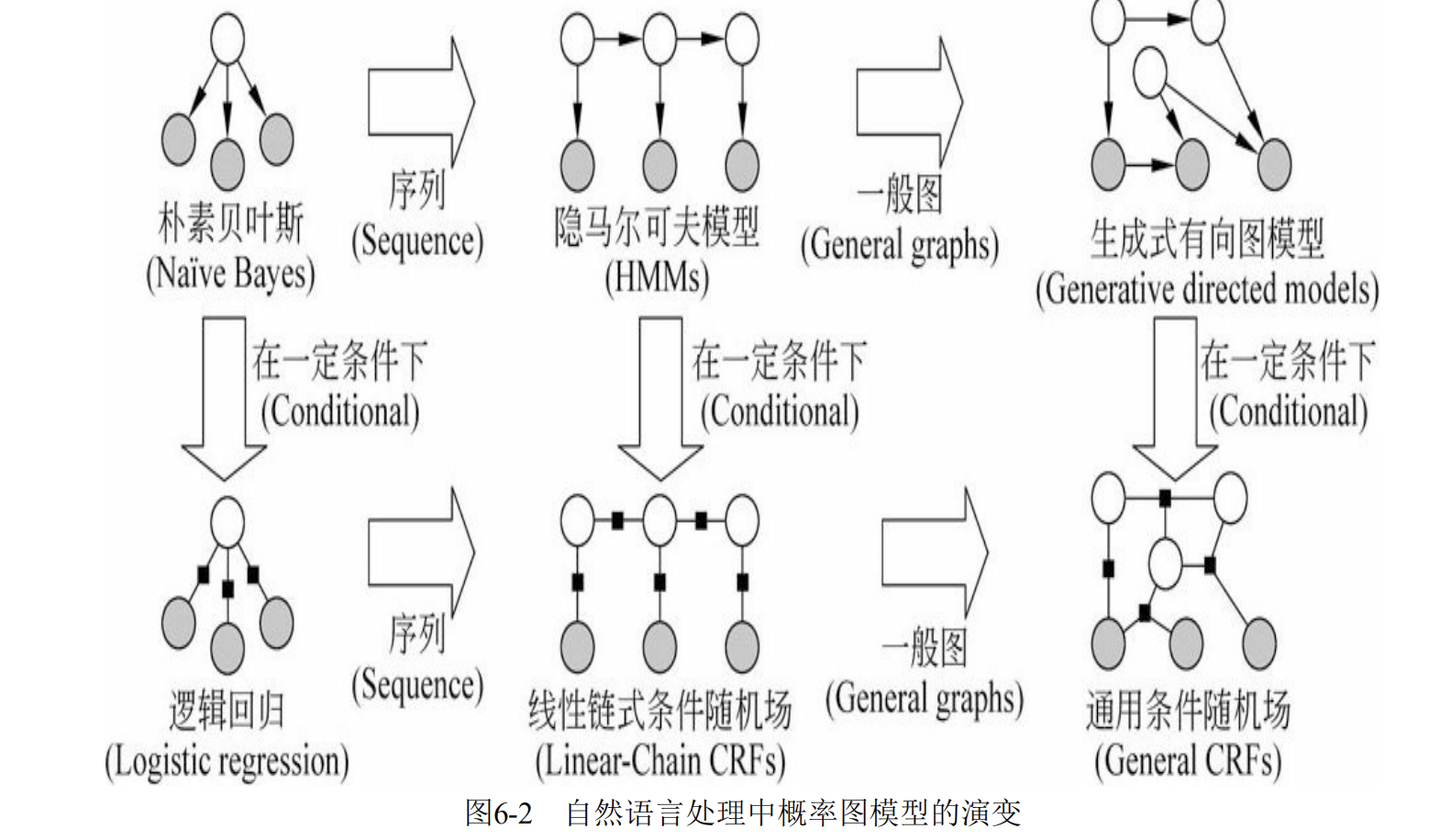
| 上面一行的是生成式模型,在一定条件下,能够转变成判别式模型。而这生成式模型和判别式模型又是什么东西呢?生成式模型假设观察序列(常常就是 label $y$)决定状态序列(常常是 input $x$),因此建模的是 $P(X | Y)$ ,比如我们之前讨论的产生正向情感极性 $y_p$ 的文本 $s$ ,就是建模 $P( s | y_p )$;判别式模型的假设恰恰相反,认为 $x$ 决定 $y$,上面的问题翻过来,给定一个文本 $s$,来判断其携带正向情感极性的概率,就是建模 $P(y_p | s)$ ,这就是一个判别式模型了。粗浅地理解的话,生成式模型就是一个生成器,典型如 n-gram 语言模型;判别式模型则可以看做是一个分类器,例如 SVM(支持向量机)。 |
接下来,我们就着重学习自然语言处理中比较常用的两类线性结构的概率图模型,正好一个是生成式一个判别式:HMM (隐马尔科夫模型)和 CRF (条件随机场)。
Hidden Markov Model
马尔可夫模型
先介绍马尔科夫模型,其描述的是一类重要的随机过程(随时间而随机变化的过程),而这种随机过程可以由一个随机变量序列来刻画。假设一个系统有限个状态 $S = (s_1, \dots, s_n)$,随着时间推移,系统的状态从一个状态转到另外一个状态,我们在每个时刻观测系统,则可以得到其状态序列 $Q = (q_1, \dots, q_T)$,一般来说,$t$ 时刻的状态会依赖之前时刻的状态,所以我们描述状态转移的时候,会刻画如下概率:
\[P(q\_t = s\_j | q\_{t-1}=s\_i, q\_{t-2} = s\_k, \dots )\]如果 $t$ 时刻状态只和 $t-1$的状态相关,则上面的式子可以改写成
\[P(q\_t = s\_j | q\_{t-1} = s\_i)\]这个系统就被称为一阶马尔科夫链,进一步地,如果状态转移的概率 $P$ 与时刻$t$无关,是一个常数 $a_{ij}$ ,则这个随机过程就可以称为马尔科夫模型,不过 $a_{ij}$ 需要满足:
- 大于等于 0 ,很直接,这就是概率的约束
- 以及 $\sum_j a_{ij} = 1$ ,从一个状态转向其他状态概率之和为 1
| 在给定状态转移矩阵 $A$ 的情况下,我们可以利用简单的概率公式来计算给定某个状态序列的概率,这里就不再展开。一个很有趣的地方是,马尔科夫模型和 n-gram 模型是很类似的。在 n = 2 的时候,实际上就是一个一阶的马尔科夫模型;而当 $n >= 3 $ 的时候,如果我们把模型表示为概率乘积 $P(w_n | w_{n-1}, \dots, w_{n-N+1})$时,那么 n-gram model 就可以视为是 n -1 阶马尔科夫模型(language 的窗口大小为 n,我们就需要看前面 n -1 个)。 |
隐马尔可夫模型
| 隐马尔科夫模型重在一个隐字,隐藏的是状态序列 $Q$,而每个状态 $q_t$ 对应会有一个输出 $o_t$,我们能够观察到的只有观测序列 $O$,如果假设可取的输出集合为 $V = (v_1, \dots, v_k)$ ,那么我们就会有一个观测概率 $P(o_t = v_k | s_t = q_j)$,类似状态转移矩阵,我们可以得到一个观测概率矩阵 $B$。再加上一个初始状态概率分布 $\pi$ (一开始系统处于每个状态的概率 $P(q_0 = s_i)$),我们就可以刻画隐马尔可夫模型 $\lambda = (A, B, \pi)$。一堆公式还是容易让人迷惑,《统计学习方法中》举了一个例子: |
假设我们有几个盒子,每个盒子里装着红白黑三种颜色的小球,每次有个人会悄悄地选择一个盒子,然后从这个盒子中选择一个球并且展示。
在这个例子里面,盒子就是状态,每次选择盒子,就是一个状态间的转移,但是这个选择的过程我们是不知道的;从盒子中选择球并展示,就是由状态产生观测结果,我们是能够看到选了什么颜色的球的。
基于此,就会有三个基本的问题:
-
给定 HMM 模型 $\lambda = (A, B, \pi)$ 和观测序列 $O(o_1, \dots, o_T)$ ,计算 $P(O \lambda)$ -
已知观测序列 $O$,估计模型参数 $\lambda$,使得 $P(O \lambda)$ 最大,这就是我们常用的极大似然方法 -
已知模型 $\lambda$ 和观测序列 $O$,求可能性最大(即 $P(Q O, \lambda)$)的的状态转移路径 $Q = (q_1, \dots, q_T)$
下面把求解这三个问题方法的核心思想做一个简要的介绍:
问题1:给定 $\lambda$ 和 $O$, 求 $O$ 的概率
显然,我们需要借助状态序列来完成对观测序列概率的估计,即
| $P(O | Q, \lambda) = \Pi_{t = 1}^T P(O_t | q_t, \lambda) = b_{q_1}(O_1)b_{q_2}(O_2)\dotsb_{q_T}(O_T)$ |
就是一系列发射概率的乘积,而注意到
\[P(O | \lambda) = \sum\_Q P(O, Q|\lambda) = \sum\_QP(O|Q, \lambda)P(Q|\lambda)\]式子就变成了枚举所有可能的状态序列,计算其出现 $O$ 的概率,如果状态集合的数量为 $N$ ,长度为 $T$,则枚举的时间复杂度是 $O(N^T)$ ,是无法高效地计算的。为什么计算量这么大?因为枚举过程中会存在多次重复计算已经算过的部分状态序列,为了解决这个问题,可以通过使用动态规划来限制搜索的范围,从而提升效率,而 DP 的计算方式有两种:
-
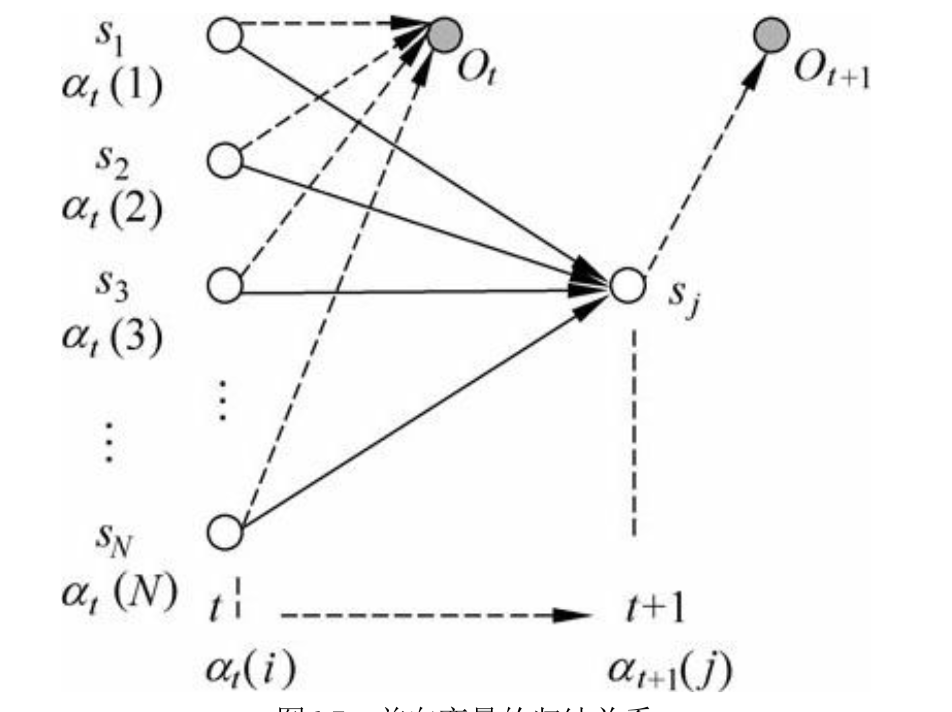
前向算法:从前向后计算,设 $\alpha_t(i)$ 为 $t$ 时刻观测序列为 $(o_1, \dots, o_t)$ ,且状态为 $s_i$ 的概率
\[\alpha\_t(i) = P(o\_1, \dots, o\_t, q\_t = s\_i| \lambda)\]则可以得到递推公式:
\[\alpha\_{t+1}(j) = \sum\_i a\_{ij}\alpha\_t(i)\]而原先观测序列 $O$ 的概率由下面的式子计算:
\[P(O| \lambda) = P(o\_1, \dots, o\_T, q\_T = s\_t | \lambda ) = \sum\_i P(o\_1, \dots, o\_T, q\_T = s\_i | \lambda) = \sum\_i \alpha\_T(i)\]我们可以通过初始的状态分布和发射概率轻松得到 $\alpha_1(s_i)$ ,然后快乐地向后递推即可,下面这张图很好地说明了这个推断的过程
-
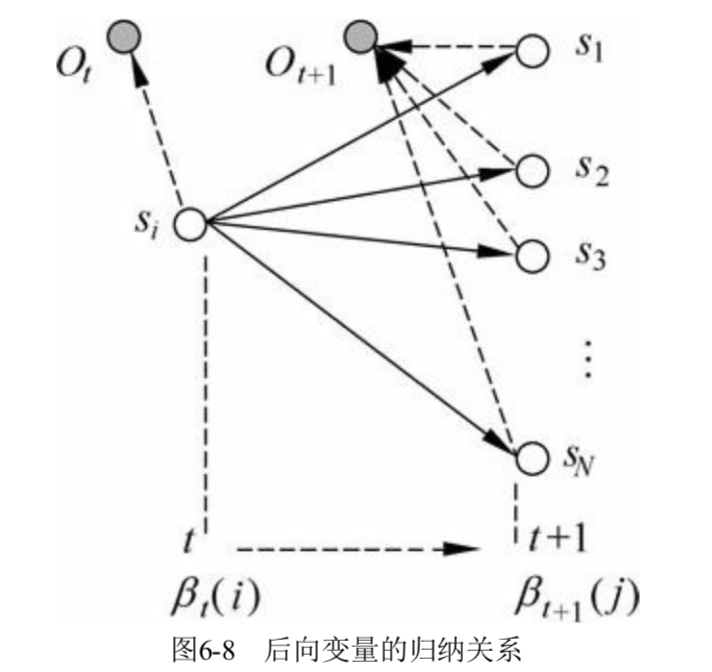
后向算法:和前向相反,是从后往前推的。定义 $\beta_t(i)$ 为给定模型 $\lambda$ ,并且在时间 $t$ 时状态为 $s_i$,模型输出 $(o_{t+1}, \dots, o_T)$ 的概率:
\[\beta\_t(i) = P(o\_{t+1}, \dots, o\_T|q\_t = s\_i, \lambda)\]则我们可以得到递推公式:
\[\beta\_t(i) = \sum\_j \alpha\_{ij} b\_j(O\_{t+1}) \beta\_{t+1}(j)\]初看可能比较难以理解,我们可以在 $t$ 时刻状态为 $s_i$ 产生输出 $(o_{t+1}, \dots, o_T)$ 分解为两个过程:
- $t$ -> $t+1$,状态从 $s_i$ 到 $s_j$,从 $s_j$ 产生 $O_{t+1}$,即 $a_{ij}b_j(O_{t+1})$
- 在 $t+1$ 时刻状态为 $s_j$,产生输出 $(o_{t+2}, \dots, o_T)$,即 $\beta_{t+1}(j)$
而我们需要枚举可能的状态转移,所以有一个求和的操作,再看下面这张图
是不是就豁然开朗了。
上述两个算法的代码就不放了,但我们可以简单分析一下时间复杂度,外层是一个从前向后(或者从后向前)对 $t$ 的循环($T$ 次),内层则是对每个状态计算 $\alpha_t(i)$($N$ 次),计算的时候需要枚举状态转移($N $次),所以复杂度为$O(N^2T)$.另外,结合前向和后向公式,我们可以获得计算给定观测序列 $t$ 时刻状态为 $s_i$ 的概率:
\[P(O, q\_t=s\_i | \lambda) = \alpha\_t(i) \beta\_t(i)\]问题2:给定观测序列 $O$ 和模型 $\lambda$,求最优的状态转移序列 $Q$
一种很贪心的想法就是,选择每个时刻概率最大的状态作为该时刻的状态,但是显然这是行不通的,因为可能两个”最佳”状态之间的转移概率为 0,所以得到的状态转移序列是非法的。因此,我们实际上需要求的是:
\[\hat Q = \text{argmax}\_Q P(Q| O , \lambda)\]我们需要优化的是状态序列的概率,而非单个概率。为此,我们同样借助动态规划,定义 $\delta_t(i)$ 为在时刻 $t$ 时 HMM 沿着某一条路径到达状态 $s_i$ 且输出 $(o_1, \dots, o_t)$ 的最大概率:
\[\delta\_t(i) = \text{max}\_{q\_1, \dots, q\_{t-1}} P(q\_1, \dots, q\_t = s\_i, o\_1, \dots, o\_t | \lambda)\]类似前向方法,我们可以得到如下递推式:
\[\delta\_{t+1}(i) = \text{max}\_j \[\delta\_t(j) *\alpha\_{ji}\]* b\_i(O\_{t+1})\]这里比较特殊的是我们需要记录一下得到最大概率所经过的路径,学过 DP 的话就知道里可以利用一个同构的数组来保存路径即可,这里就不赘述。
问题3:参数估计,给定 $O$ ,找到使其出现概率最大的参数 $\lambda$
很直接地,上最大似然估计即可:

但是因为 $Q$ 是观察不到的的,所以这个方法是不能用。如果我们有神经网络的话,就可以很轻松地利用梯度下降来更新模型的参数(可以把转移概率、初始分布、发射概率都视作模型的参数),从而得到一个近似解。所幸我们还有 EM 算法,其思想和神经网络有一些类似,同样是通过迭代来更新参数,只不过这里不再是拟合 groud-truth,而是通过上一步地参数来估计上图中的参数,得到新的参数来更新自身。
具体的实现就是 Baum-Welch 算法,其核心思想就是在状态序列中打开一段,计算给定 $O$ 和 $\lambda$ $\epsilon_t(i, j)$ 在 $t$ 时刻状态为 $s_i$ 且 $t+1$ 时刻为 $s_{j}$ 的概率:
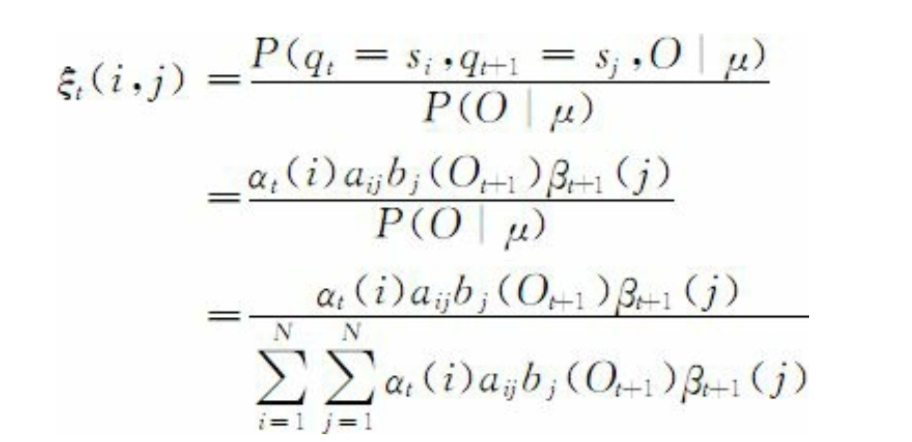
从而,我们可以得到给定 $O$ 和 $\lambda$ 情况下,在时间 $t$ 时状态为 $s_i$ 的概率 $\gamma_t(i)$
\[\gamma\_t(i) = \sum\_j \epsilon\_t (i, j )\]则我们可以用下列式子来估计模型的参数:

看到这里的人我想不多了吧,所以我也懒得手打公式了(逃
条件随机场 CRF
| 之前说过条件随机场就是在意一定条件下,将 HMM 的生成式模型改成判别式模型,换而言之就是我们不再根据输出序列 $Y$(之前的观测序列) 来推输入序列 $X$(状态序列),而是建模 $P(Y | X)$。进一步,条件随机场的定义为:无向图 $G = (V, E)$ ,$V$ 中每个节点都对应于一个随机变量 $Y_v$,如果以观察序列 $X$ 为条件,则 $Y_v$ 满足: |
其中 $w \sim v$ 表示与 $v$ 相连的节点。说人话就是,随机变量 $Y_v$ 和 $X$ 有关,并且也和与其相连的随机变量有关。举个例子就是,词性标注任务,一个词的词性,除了与这个词 ($X$) 有关以外,也和其相邻的词性标签有关。拿图说话就是:
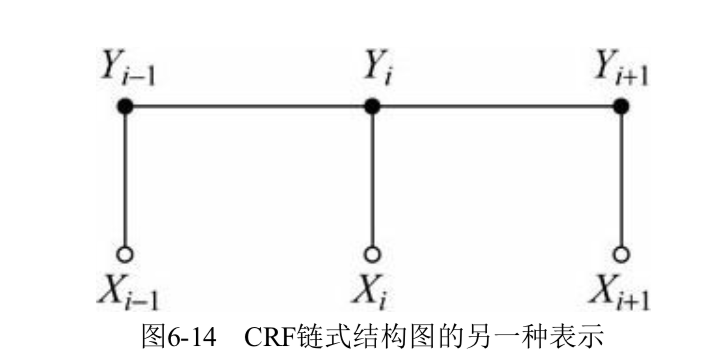
对于 CRF,到这里就已经足够我们将其应用到一些序列标注问题上了,所以就不再放公式了。接下来就来看两篇 Paper 来缓解一下被公式统治的恐惧。
LSTM-CRF for Sequence Labeling
首先我在学习 CRF 之前,一直不知道为什么词性标注任务需要用 LSTM+CRF 这样的结构,我理解为词性标注的输入和输出都是序列,那么用 Seq2Seq 的方法做不就可以了吗?《Bidirectional LSTM-CRF Models for Sequence Tagging》 这篇文章给了我答案,看下面两张图:
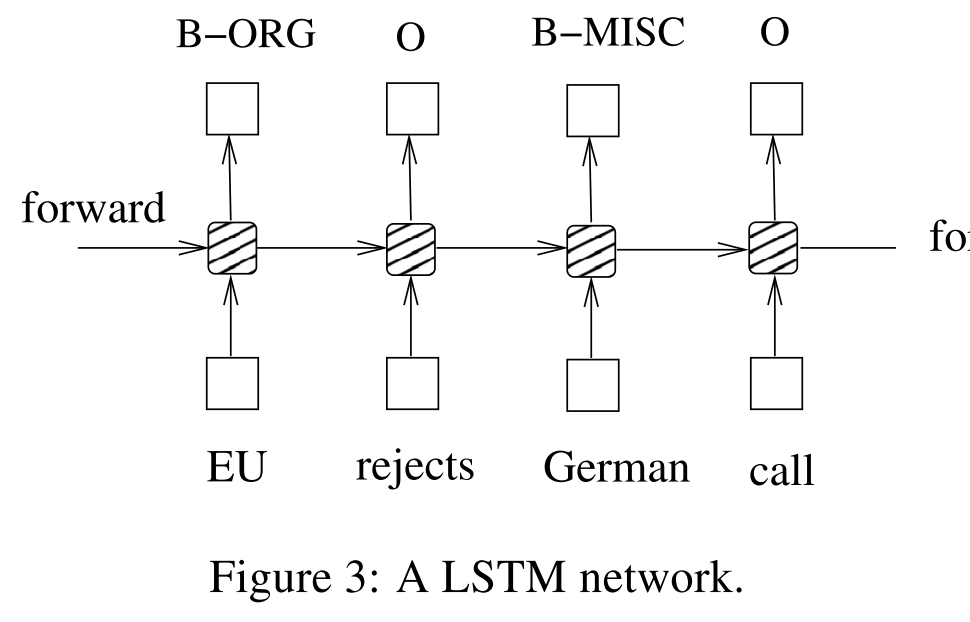
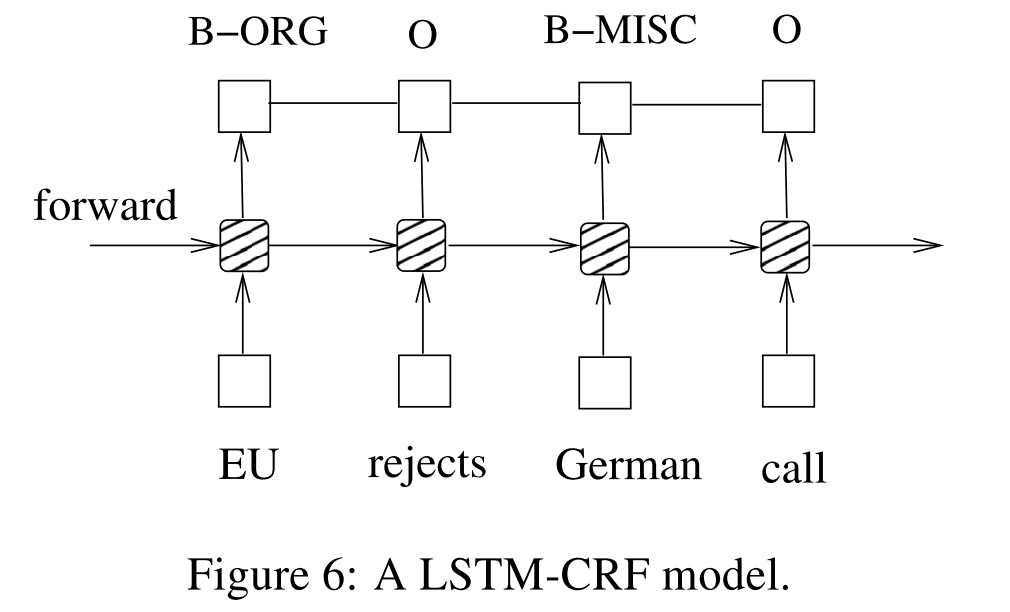
看到区别了吗?区别就是前者 Label 之前是没有边相连的,而后者边之前是有关联的,这能解决什么问题呢?比如说,在英文中形容词后面跟的往往是名词而不是动词,这种标签之间的关系,就是 CRF 所考虑的。另外,实体识别中,也会有类似的情况出现,一个人的名字还没结束的情况下一般不会出现另外一个地名。因此,CRF 就显得非常重要了。
上面的文章提出,我们把 LSTM 的输出看做是状态到 label 的发射概率,而 CRF 层其实就是一个 label x label 大小的矩阵,建模的就是 label 之间的转移概率。有了这些概率和权重之后,就相当于有了之前 HMM 中的 $\lambda$,然后我们通过问题 2 的解法求出最优的词性标注序列,然后再通过 MLE 来更新参数即可(因为这个问题还是一个 Seq2Seq,所以 loss 还是 label-wise negative log-likelihood)。其实可以看到,神经网络在这里面扮演了两个角色:
- 特征抽取,通过 LSTM 和 CRF 层来学习发射概率和转移概率,而不用手工的去定义规则,做特征工程
- 通过 SGD 等梯度下降算法可以很好地优化参数,避免使用 EM 算法的繁琐,交给 GPU 去算就是了
另外一篇《End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF》和这篇文章相比,没有什么东西就是在 $X$ 的表示上增加了 Character-level 的 CNN,并且把实验做的更加丰富,从而水了一篇文章发表在顶会上。不过,很多现在看来很直接的想法,在以前依旧是很不容易的,因为我们依旧是站在了巨人的肩膀上。
最后,附上 PyTorch 的 LSTM-CRF 教程,有兴趣的同学可以手搓一下,加深印象。
Summary
这篇文章主要是把两本书中的相关内容过了一篇,权当笔记,虽然有着大量的公式,但其实根源还是贝叶斯概率公式,所以也没有想象中那么复杂。之前看不下去就是因为心不静,抽出一点时间,手推一遍,总是能看懂的。另外,写的比较仓促,如有疏漏,敬请指出~