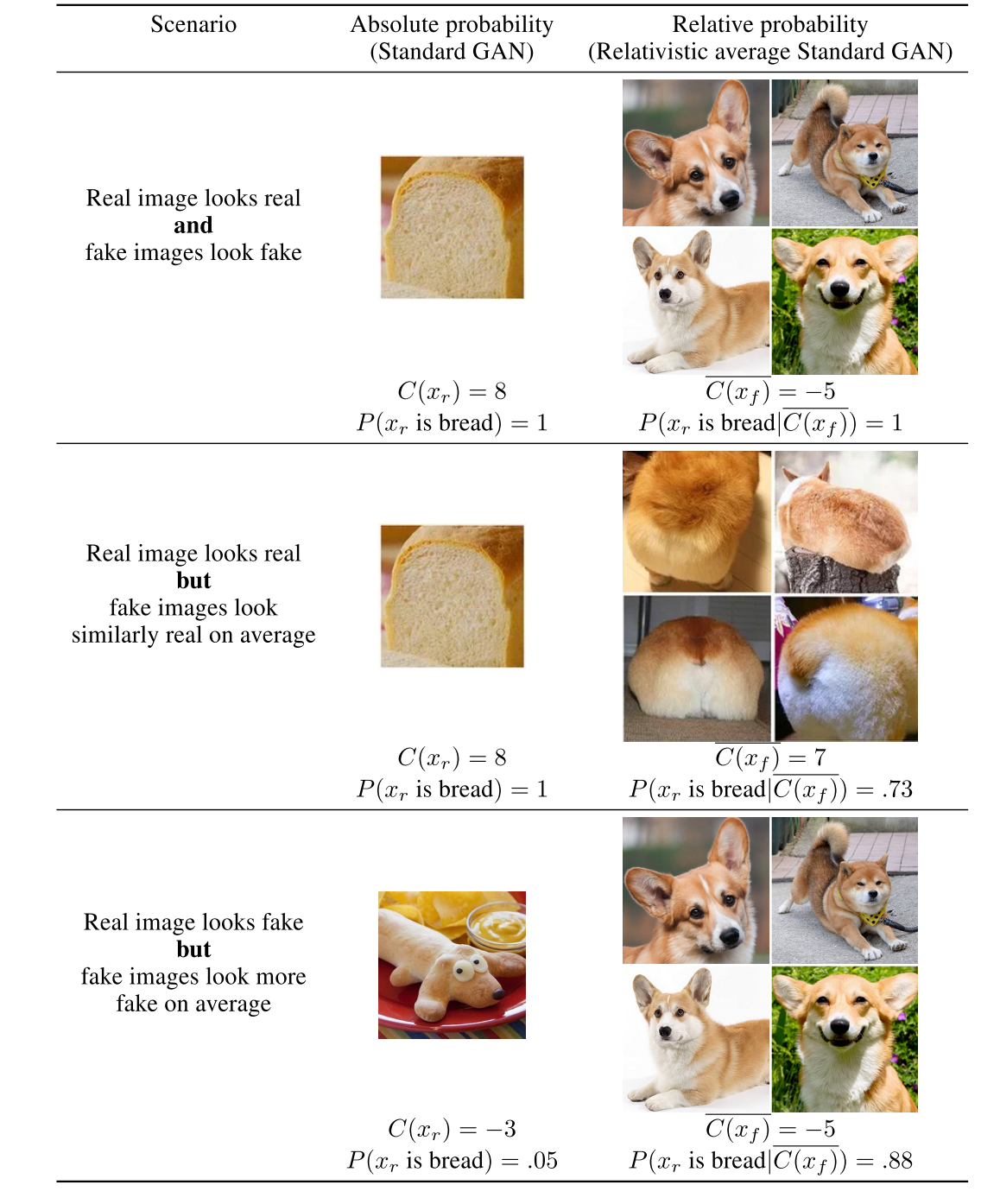
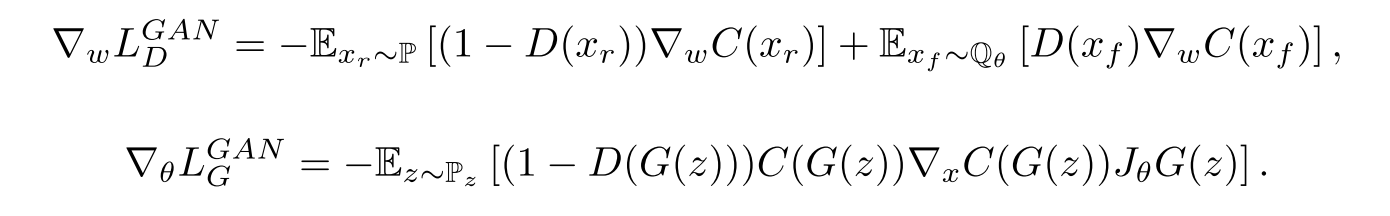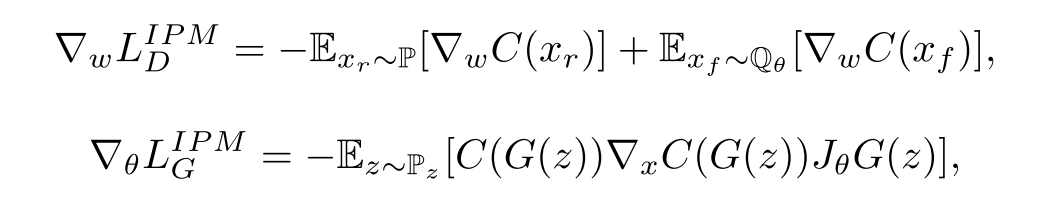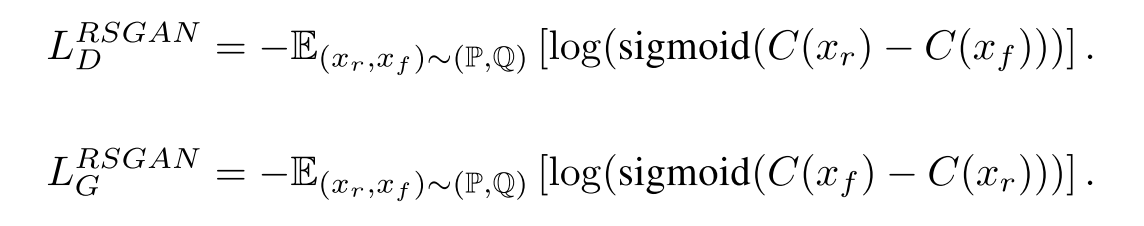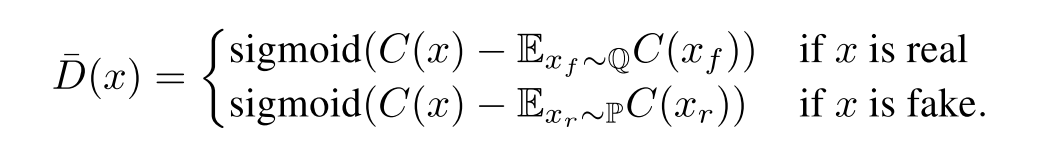文章说标准的 GAN(SGAN) 在 Generator(下文用 G 代替) 生成的样本越来越逼真的时候 Discriminator 缺了个东西。什么呢?相对的概念,先来看下面这张图片:
可以看到,我们的 real data 是面包,fake data 是柯基(好萌啊2333),$ C(x) $ 越大则说明是面包的概率越大。图中列出了三种情况:
真的面包,真的柯基:这种情况二者的区别很明显,因而 $ P(bread
\bar C) = 1 $
真的面包,柯基屁股(很像面包):这种情况区别就没有第一种那么明显了,因而 $ P $ 有所下降
像狗的面包,真的柯基:和第二种情况类似,相对的区别度降低了, $ P $ 同样有所下降
有了一个模糊的印象之后,我们展开说说这个相对究竟是什么。
Arguments of RaGAN
相对,一言以蔽之:Discriminator(下文中用 D 代替)衡量样本真实性的时候,应该要同时利用 real data 和 fake data,衡量的由绝对的真假变成相对的为真或为假的概率。 作者从三个方面论述了其观点:
Priori Knowledge
先验知识的利用,即每次我们喂给 Discriminator(下文中用 D 代替) 的样本中,基本上是一半 real data,一半 fake(Generator generated)。也就是说,不知道这个前提的话,那么如果 G 生成的样本(比如说图片)能够以假乱真的话,那么 D 会认为所有的样本都是 real 的,而如果知道这个前提,那么当 fake 比 real 更 real 的时候,discrinimator 应该给 real samples 打低分(认为他们是 fake) 而不是认为所有的 samples 都是 real。因为在看到了更 real 的 fake samples 之后,相对地,利用先验知识,我们会认为不那么 real 的 samples(比如狗面包)是 fake 的。而 SGAN 的训练中并没有利用到这一部分先验知识。
Divergence Optimization
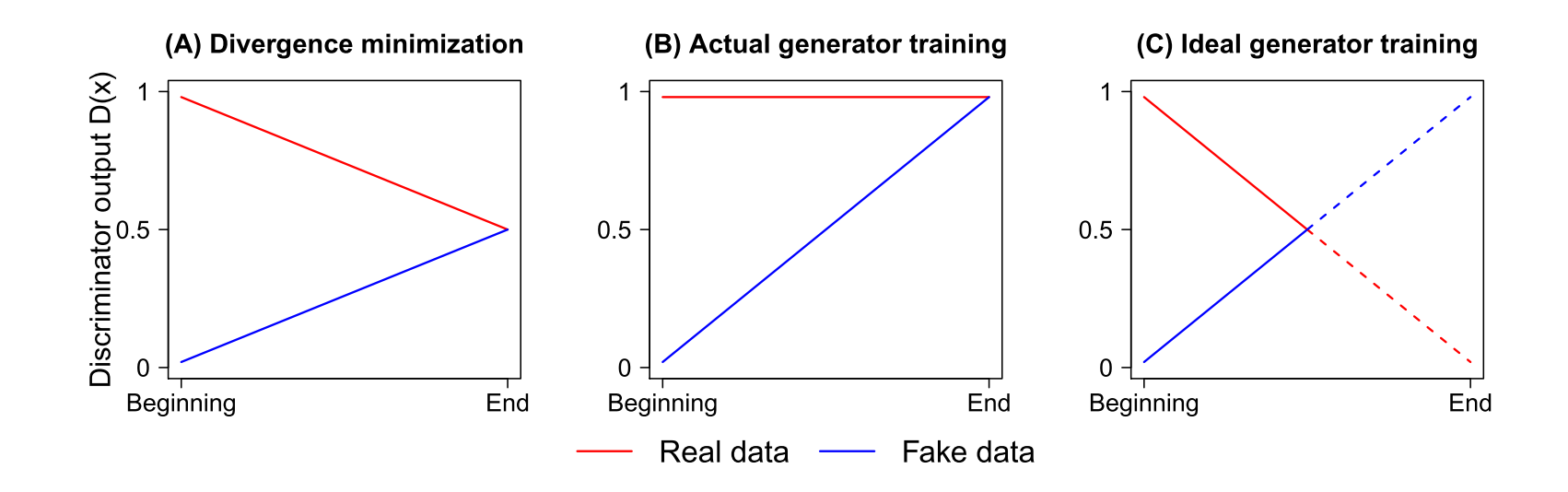
我们知道,SGAN 在训练 D 的时候事实上是在 minimize 生成器分布和真实数据分布的 JS-Divergence,而 JS-Divergence 在两个分布相同时达到最小值,其表现是 D 无法区分 real data 和 fake data,认为其为真的概率均为 0.5;JS-Divergence 在两个分布差异较大的时候较大,即 D 认为 real data 为真的概率为 1,而认为 fake data 为真的概率为 0。理想的训练过程是如下 (C) 图所示:
不过这个时候,我们发现 GAN 中 D 的功能已经悄然发生的改变,由原来的:衡量输入数据为真的概率,变成了输入的数据与其对立类型随机的一个样本(如果输入为 real data,那么衡量其比 fake data 更像真的概率,反之亦然)相比更像真的的概率。那么,更一般地,我们利用对立类型的平均真实度来作为更可靠的参照对象。
所谓平均真实度,就是对整个(或者一个 mini-batch) real data 和 fake data 求其 $D(x)$ 的数学期望,这样的估计能够更加整体的反映训练在这一时刻生成器生成的 fake data 的真实程度。同样,我们可以轻易地将其泛化到别的函数之上。最后整个算法流程如下:
Toy Demo
原作给了很多例子来说明 RaGAN 的效果,并且也提供了相应的代码。这里我就拿 MNIST 做一个小小的 Demo,在原版的 GAN 的 demo 上做了一个很小的改动,就是把 loss 计算中的 logits 进行对应的相减。