
论文杂记
记录最近读的一些文本生成相关的 Paper。
Sentiment Modification
这是一个比较有趣的问题,定义如下:
The task of sentiment modification requires re- versing the sentiment of the input and preserv- ing the sentiment-independent content.
但是存在几个难点:
- 没有 Parallel 的语料,比如“松林食堂的生煎很好吃”是 positive 的,对应的 negative 例子可能就是“松林食堂的生煎不好吃”,而这种语料是很难成 pair 出现的。
- 没有平行语料,可能说,那我们把情感词直接换成 opposite 是不是就可以了,可能上面的例子可以 work,但是这个 “The food is cold like rock” 变成 “The food is warm like rock”就很不恰当了。
为了解决这两个问题,孙栩老师组有两篇 Paper,尝试通过不同的方式来实现 Sentiment Modification 这一任务,而其核心都是通过将句子去极性后,在进行极性的添加或者说是修改。
Unpaired Sentiment-to-Sentiment Translation: A Cycled Reinforcement Learning Approach
这篇文章通过 RL 的方式来实现没有 Parallel 语料场景下的 Sentiment Modification:
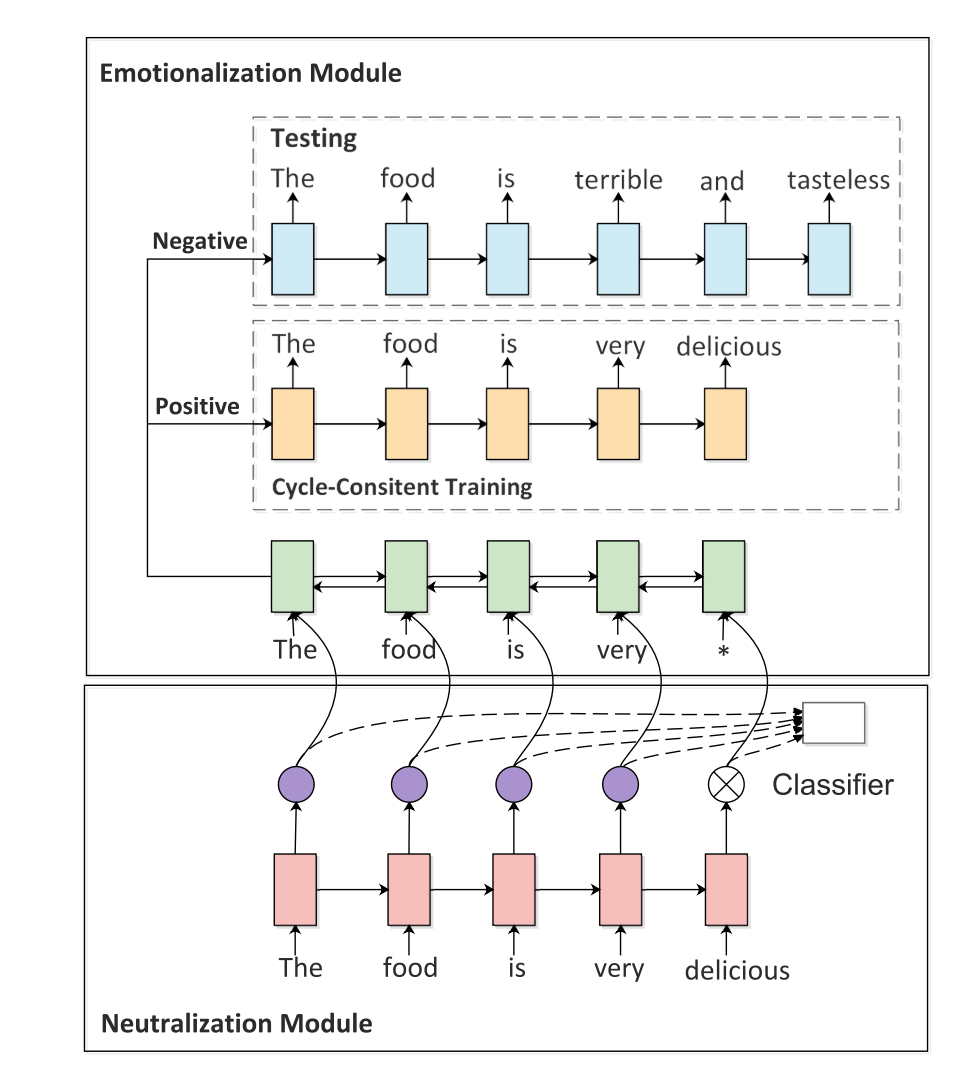
比较有意思的是这个 Neutralization Module,是怎么实现这个情感词的去除呢:通过 Attention Weight。我们知道,情感分类中经常对各个 hidden state 做一个 weighted sum 来形成最后的一个 logits,而这个 weight 就能够反应其对情感极性的贡献程度。那么如果某个词的权重大于平均权重,就可以将其看做是一个情感词,去除掉之后得到不带极性的句子,这个思路非常自然。
Emotion module 的任务是根据去掉情感词的句子和要求的情感进行修改,在 pre-train 阶段通过和原句对比计算 loss 来进行基本的生成能力的训练。而后,怎么生成另一种极性的句子呢?通过 Emotion module 和 Neutralization Module 的相互提升,文章称之为 Cycled RL,将两个模块视为两个 agent($N_\theta$ 和 $E_\phi$),具体的做法如下:
- 让 $E_\phi$ 根据去除情感词后的输入 $\hat x$ 生成两个极性相反的文本 $\overline x$ 和 $x$,而通过这两个句子来计算一个 reward。这个 reward 需要考虑到两点:文本的质量和情感极性是否正确,因此其 Reward 最后是一个 BLEU 和 sentiment classifier 给出概率的调和平均值。这个 reward 就作为 guide signal 来负责提升 $ N_\theta $。
- 对于 $E_\phi$ 来说,原句依旧可以视作是一个 supervision,因而其目标就是通过 $N_\theta$ 给出的去除极性的句子来 recover 原句,通过生成原句 log-prob 作为 reward 来进行 $E_\phi$ 的训练。
这样的方法在几个数据集上都取得了不错的效果,但是在 Sentiment Accuracy 方面有所欠缺;同时,作者也提出对于一些具有 sentiment-conflict (自相矛盾,e.g. “Outstanding and bad service”)和中性句的效果不好(因为没有情感词可去),这也是意料之中。
Learning Sentiment Memories for Sentiment Modification without Parallel Data
对于 Emotion Word 的选取和上篇文章是一样的思路,首先选出 emotion word,加权求和得到一个向量表示 $s^{pos}$ (以 positive 为例子),而后利用此计算一个情感记忆 $\textbf{M}^{pos}$ 来辅助 Seq2Seq 结构 Decoding 阶段:
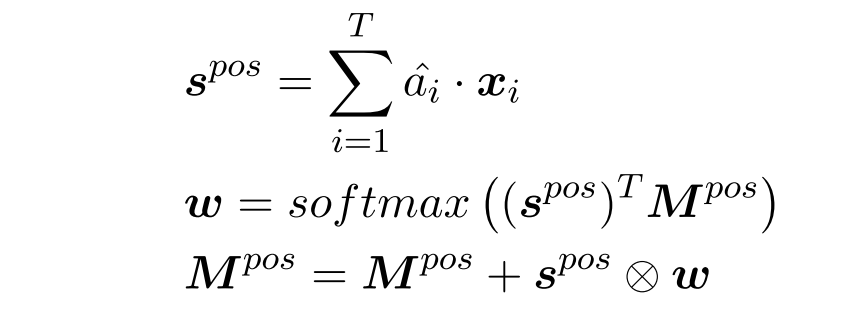
而 Context 信息则由 $ 1- weight$ 的加权和得到:
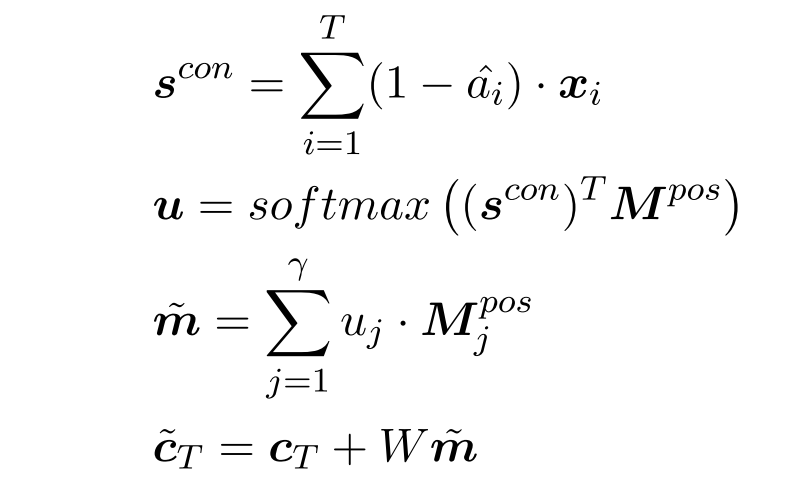
再以此做了一个类似 attention 的操作,从而能够从情感记忆中提取出和上下文搭配的情感词来。最终得到一个 $\tilde c$ 作为 decoder 的 initial state。
相比之前的 Cycled RL,这篇基于 Seq2Seq 进行 Sentiment Modification 的文章在 Decoder 的 initial state 上做了些文章,提供关于 sentiment 的信息在里面,帮助 decoder 生成具有极性的文本。
IRL For Text Generation
IRL,Inverse Reinforcement Learning 逆向强化学习,其核心是在于通过学习 reward function 而不是 manually defined 来指导 policy 的更新。其框架又和 GAN 非常的类似,其元素有一种对应关系:
| IRL | GAN |
|---|---|
| Trajectory $\tau$ | sample $x$ |
| Policy $ \pi $ | Generator $G_\theta$ |
| Reward $r_\phi$ | Discriminator $D_\phi$ |
既然原先 GAN 能用在文本生成,那么 IRL 也可以;复旦大学邱锡鹏老师最近的一篇 Paper 《Toward Diverse Text Generation with Inverse Reinforcement Learning》就尝试将 IRL 框架和文本生成结合,进行尝试:
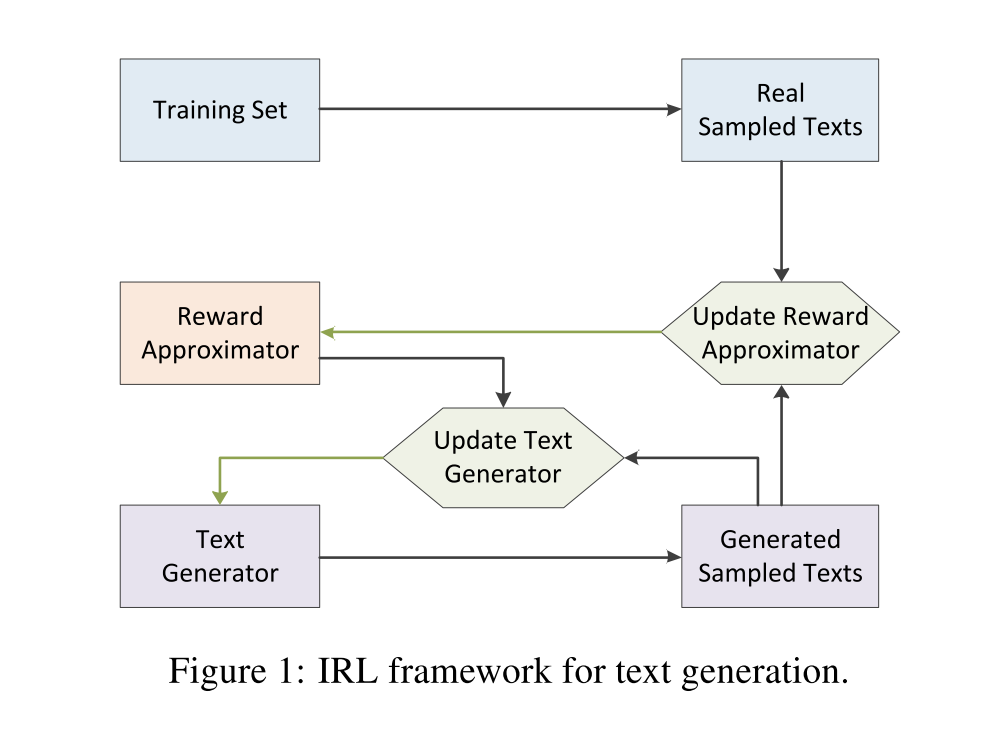
实现思路其实也很简单,将原来 SeqGAN 中的 Discriminator 换成 IRL 中的 Reward Approximator,由此得到一个 $r_\phi(s_t, a_t)$,对一个文本序列进行求和得到对应的 $R_\phi(\tau)$ ,据此对 Generator 进行更新即可。但是用 IRL 有什么好处呢?
-
解决 Reward Sparsity 问题:这里的稀疏可能不是类似传统 RL 中很多个 action 都没有 reward,我认为是区分度的问题,如 DP-GAN 中所谈到的,很多时候 Discriminator 的 reward 不是 0 就是 1,这种极端的分布会致使 Generator 得不到进化的动力,即其 guide signal 比较弱,致使生成的文本质量不高。文章也谈到了一些工作来增强这个信号,比如 LeakGAN、RankGAN 等。而 IRL,如果能够学到一个比较好的 reward function 而不是通过一个很强力的 classifier 来做出非黑即白的判断的话,确实是能够缓解这一问题,而这一论点文章尚无实验(reward plot)来支撑,有待后续继续研究。
-
解决 Mode Collapse 问题:这是一个老大难问题,我对于此的观察和理解是:GAN-based model 倾向于生成重复的句子,因为在最大化生成器的目标函数时,会将 G(X) (生成某个句子的概率)推向较大的一侧,即少数的几种句子 domain 整个生成空间。而基于这种理解的一种解决方案就是 SentiGAN 中的 Penalty-based Objective Function,迫使 G(X) 变小,更为均匀的分布,来缓解 mode collapse 问题,这一点在我的实验观察中得到了验证。IRL 中 Generator 的 Objective Function 是两项之和,前一项可以看做是最大化生成的文本的 reward,和 GAN 类似。后一项则被称之为 entropy term,作者说这一项能够鼓励 Generator 生成多样的文本。
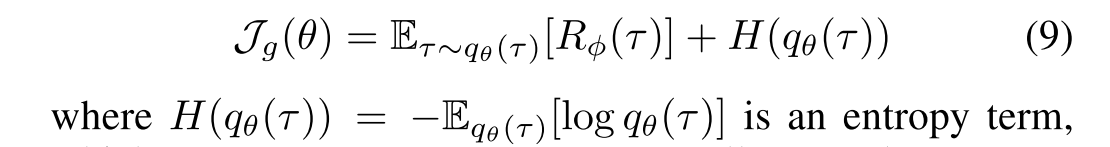
利用熵的极值性,当所有事件的概率都相同时,熵最大(即事件发生的不确定性最大),这样概率分布就趋向于均匀,可以视作缓解 mode collapse 问题。
Query and Output
前面所述的三篇文章都有一个共同点,即在进行文本生成的时候,都是生成一个词表上的概率分布,对其进行采样得到生成的词,而这会带来什么问题呢?孙栩老师组的 《Query and Output: Generating Words by Querying Distributed Word Representations for Paraphrase Generation》指出两点:
首当其冲地,参数量巨大:由低维(一般数百左右) hidden representation 映射到 word space (高维,一般词表大小在数万左右),其参数量是巨大的(例如用一个全连接层做 map,二者相乘,即是百万级别)。这会带来训练速度缓慢,收敛困难的问题;其次,word distribution 是一个巨大的 vector,其每个位置上代表了对应词的概率,而这个概率与概率之间是没有什么关联的(原文中写的是 irrelevant to each other,我觉得只是没有显式地考虑其他词的概率,事实上这个 distribution 是从 hidden representation 得来,其中应该包含这个关联信息),因而无法学到语义上的关系。
为了解决这两个问题,这篇文章提出了利用 query 方式来进行 word 生成。
query 向量由当前的 hidden state 和 cell state 构成:
\[q\_t = tanh(W\_c\[s\_t;c\_t\])\]而要查询的 Key-Value Pair 对应的就是 word $w_i$与 对应的 word embedding $e_i$ ,通过一个 score function:
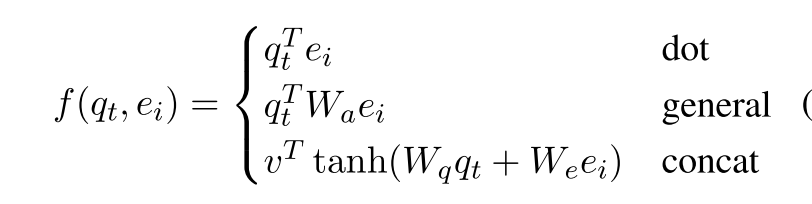
最后通过 softmax 层得到词表分布:
\[p(y\_t) = softmax( f(q\_t, e\_i))\]这种检索式的生成带来的显著好处就是参数量的下降,和原先百万级别的全连接层参数相比,这里至多只有 $W_q$ 、 $W_e$ (concatl)和一个 $v$,假设 hidden size 和 embedding size 都是 256,其参数量也就是 256 x 256 x 2 + 256,在十万左右。不过这也意味着我们需要对每一个 word embedding 都做一次 query,似乎是在用空间换时间;但是好在可以通过向量并行化进行操作,所以最终的收敛速度还是要优于原先的 Seq2Seq。同时,这个 query 是在 word embedding 层面上做的,各个词之间的 relation 能够得到得到一个强化(比如 semantic meaning 类似的词概率 query 后的分数比较相近),对应地缓解先前的各个词的概率关联度不高的问题。
另外,可以看出,这种 Query 式的 Attention 有一点《Attention is All you Need》的味道在里面。