
定制 RNN Cell
之前写过一篇 IndRNN 的文章,第一次照着开源代码实现了自己定制 RNN,其实也很简单,就是把 RNN 实现里的 __call__ 函数进行修改,每一个时间步的全连接 matmul 改成 element-wise 的 * 即可,IndRNN 的GitHub,是一个很不错的练手参考。最近做文本生成的时候遇到两个经典模型,在复现的时候同样是需要对 RNN 的结构进行改动,这篇文章就记录实现的一些细节。两个模型可以分成两类:在时间步的输入上进行操作和修改 Cell 内部结构。
Add Extra Input
第一个模型是 MTA-LSTM,IJCAI 2018 的一篇关于主题写作的文章,也有开源实现,但是因为其代码版本比较老,并且 inference 阶段的代码比较难并行无法和现有的 seq2seq 的接口结合使用。So,需求就是实现其代码并且尽可能地需要和seq2seq 接口符合以便于后续的使用。模型的结构如下:
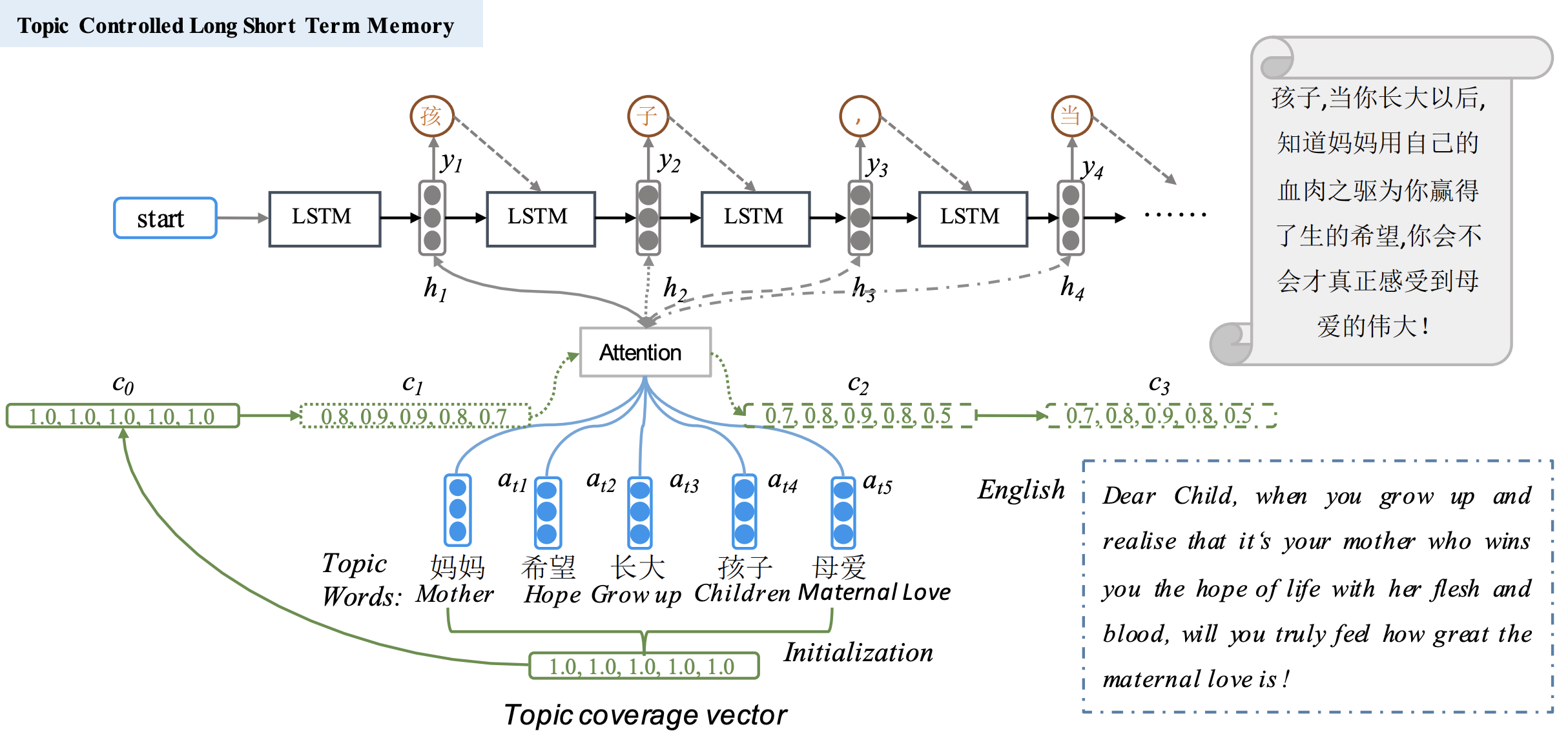
论文的核心思想如下:
- 根据主题词进行文章写作,利用 LSTM 作为生成器
- 在每个时间步,将 Topic Word Embedding 和 Inputs 拼接在一起交给 LSTM 进行生成
- 为了控制主题信息的流动,会维持一个 Coverage Vector,来表明哪些主题已经使用过哪些尚未被表达出来,从未让写出的文章主题信息更加明确
我的实现版本代码已经放在了 GitHub,下面主要记录一下实现的思路。
首先明确一点,为了和现有的 seq2seq 接口匹配,必然是无法去修改 LSTM Cell 的 __call__ 函数的,因为目前的 dynamic_decode 函数对其中的 cell 每一个时间步都会调用 cell(inputs, state) ,也即我们无法在函数参数列表中增加我们想要的额外的参数。怎么做呢?利用 Wrapper!类似装饰者模式,我们在 LSTM Cell 外面包上一层,通过这一层来对 LSTM 的输入进行操作。下面是代码:
|
|
为了节约篇幅,省去一些代码,主要看两个部分:
-
__init__函数:我们在这里传入了大量参数,其中包括了:- cell:实际 RNN 的操作是由这个 LSTM cell 完成的,我们的 wrapper 只是夹在中间进行一些小小的修改。
- 主题词的 embedding:这是每一步计算需要用到的信息,并且是固定。
- 一些要使用到的 variable:为什么 variable 从外部传入而不是定义在
__call__函数之内呢?因为 training 和 inference 阶段,我们会重新 wrap 一下我们的 cell,至于为什么,先按下不表。如果在内部定义的话,则 training 阶段学到的权重无法在 inference 阶段使用(其 name scope 是不一样的),inference 使用的依旧是初始化得到的权重,等于白学。
-
__call__函数:在这里我们进行每个时间步的mt的计算,并且将其和 inputs 进行拼接作为额外的信息,其中计算的细节就是对照公式进行实现的。这里有个坑需要谈一下:TensorFlow 不支持一个 Tensor 出现在多个 Loop 中。而如果我们之前不对 inference 阶段的 cell 重新进行包装的话,则 coverage vector 将会出现在 training 和 inference 的循环中,无法构建计算图。为此,我们才需要对 cell 进行重新 wrap:1 2 3 4 5training_cell = MTAWrapper(self.decoder_cell, topic_embedded, self.v, self.uf, self.query_layer, self.memory_layer, mask=masks) decoder_pt = tf.contrib.seq2seq.BasicDecoder( cell=training_cell, helper=helper_pt, initial_state=self.initial_state, output_layer=self.output_layer) # 重新 wrap,并且把之前习得的 weight variable 通过构造函数传入 infer_cell = MTAWrapper(self.decoder_cell, topic_embedded, self.v, self.uf, self.query_layer, self.memory_layer, mask=masks) decoder_i = tf.contrib.seq2seq.BasicDecoder( cell=infer_cell, helper=helper_i, initial_state=self.initial_state, output_layer=self.output_layer)所以我们才会需要重新传入 weight variables。最后,计算完
mt之后,直接拼接交给cell去调用每一时间步就 ok。
Add Extra Gate
对 LSTM 的结构进行修改,听着很有挑战性吧,这次不仅是要增加一个额外的输入,并且还需要添加一个额外的门来控制额外输入信息的流动。SC-LSTM 是一篇发表在 EMNLP 2015 上的文章,也是做类似的主题生成问题,模型图如下:
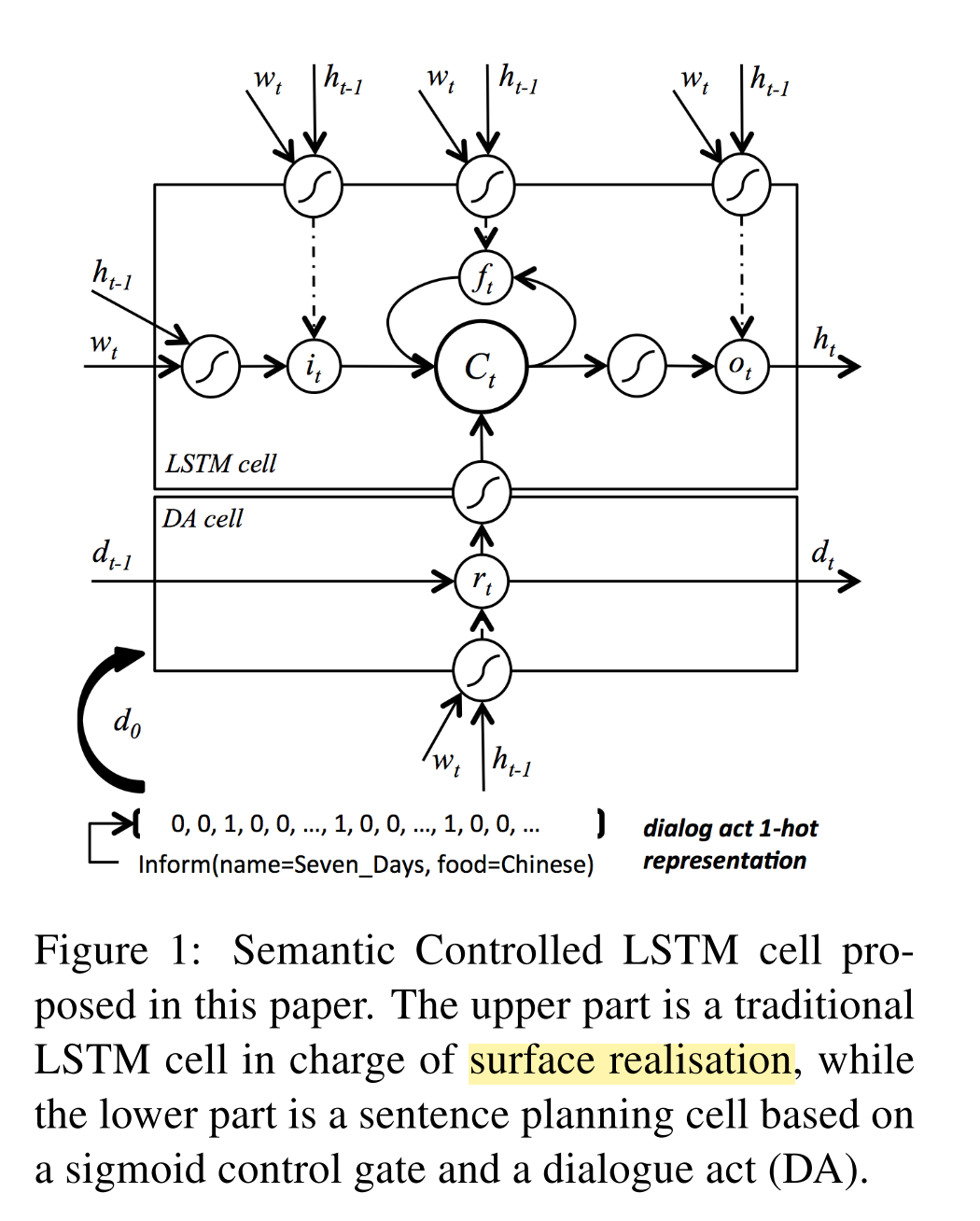
这里的额外输入就是 action vector,一个 one-hot 的向量来表明主题信息,额外的 gate 就是图中的 $r_t$,其对输入的 action vector 根据当前的输入以及之前的 hidden state 计算一个值,控制 topic 信息的流动,最后这一信息经过 gate 之后会参与的新的 hidden state 的计算之中。这次,我们必须对 __call__ 函数的进行修改了,因为不再是简单的输入拼接,而 LSTM 内部的 hidden state 的计算过程也需要依赖这个 action vector。先来看代码:
|
|
其中的核心就是我们申请了一个额外的变量 w_d,并且在 candidate 的计算之中加上了一项额外的 tanh 项,这是和文章的公式对应的:
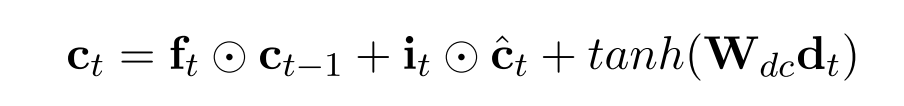
但是修改了 LSTM Cell 的 __call__ 函数之后,就和 seq2seq 接口不匹配了,依旧是借助 Wrapper 来实现接口的匹配,并且额外的 gate 也在 wrapper 中进行实现:
|
|
和之前一样,在构造函数之中我们传入了 one-hot 的 action vector,并且获取一些 variables,理由和之前一样,action vector 每步都要更新,但是不能出现在两个循环之中。__call__ 函数的结构和原先的 LSTM 保持一致,这样就能够和 seq2seq 的接口配合着使用,而在内部,根据文章的公式设置了一个 r_t 作为 gate 来控制 topic information:
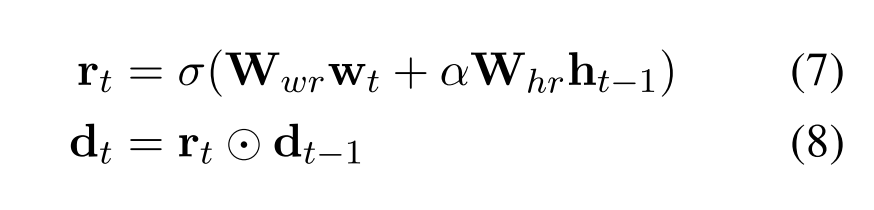
使用的时候,同样地,我们可以通过使用 ActionWrapper(SCLSTMCell(hidden_state)) 来进行使用。
Summary
至此,我们已经展现了如何利用 TensorFlow 的 Wrapper 对象来 RNN cell 功能的修改,同时能够通过接口参数的设计来让自定义的 RNN cell 和其他的 API 一起协作起来。这个 Wrapper 类,实际上就是装饰者模式的一种应用,一层一层地包裹住来增加功能并且能够屏蔽接口的不同。踩到的坑也就是在文中提到的:
- 同一个 Tensor 对象不能出现在不同 Loop 中
- 使用 Wrapper 对象的时候注意内部定义的 variable,可能需要通过外部传入来使学到的参数进入到后续的使用中(training 和 inference)
复现这两篇 Paper 的过程中主要参考了 RNN 的源码(似乎新旧版本的 API 还有不一样?),虽然之前也有读过,但自己写一遍又是不一样体验。希望以后多写写这样的代码~