
Knowledge in Neural Language Models
先验知识和当前盛行的 Neural NLP Model 的结合是一条必由之路,最近接触到 Yejin Choi 的一系列工作,并且看了她的一些 Talk(PS:真的是又有才又好看!),觉得非常有意思,将一些内容和 Paper 的阅读感悟整理如下。
The Missing Component in NLM Models
这几年来 NLP 的进展很快,包括在机器翻译、阅读理解等领域的 SOTA 都是能够达到甚至是超过人类水平的,绝大多数的 Model 都是基于 Seq2Seq 的 Framework,即使是说把传统的 RNN 替换成 Transformer,也依旧是在 Seq2Seq 这样一个框架之下,而对于像机器翻译这样的问题,我们喂给 Transformer 大量的数据之后,是能够习得一个非常出色的翻译模型的。但是,在 Neural Language Model 领域,典型如 Data-to-Text 任务, 目前的模型性能还是差强人意。例如根据一系列的 Keyword 来生成篇章级别的作文这个问题,模型产出的文章别说人类水平了,就连基本的逻辑、连贯性都很难达到合格的水平。即使是 GPT-2 这样 Huge Amount Data 喂出来的模型,前后文的关联性依旧是一个严重的问题,拿独角兽那个例子来说,后面一句就说这个物种有四个角,这是一个明显的逻辑错误。为什么这些生成任务和之前的 NMT 和 QA 差距如何之大? Yejin Choi 提到有两个主要的问题:
-
Information Gap:拿 NMT 来说,我们可以认为 source 和 target 两端文本所携带的信息是大致相当的,对于 Summarization 来说,则可以认为 target 所携带的信息是要少于 source 的,在这两个任务上,source 的信息是足够的;而对于像主题词写作这样的任务来说,几个 keywords 所包含的信息寥寥无几,和 target 端所需要携带的信息相比,是远远不足的。这就是 Information Gap,target 端所携带的信息大于甚至是远远大于 source 端。而如何填补这个 Gap 呢?思考一下我们在写命题作文中的时候,都是要从脑海中疯狂搜刮库存,才能写出像样的文章,那么 Neural Model 是不是也需要这样的一个知识的库存?
-
Alignment Between Input and Output:这个其实是 Information Gap 的另外一个视角,依旧拿 NMT 的中英翻译来说来说,”香蕉是绿的“ 对应的英文翻译是 ”Bananas are green”,这种 Alignment(对应关系)往往会通过 Attention Mechanism 来建模,所以这也是 Attention 在 NLP 中盛行的一个原因。而如果是一个 Dialogue 任务,对于同样的输入“香蕉是绿的“,那么正常的人类回答可能会是“不,香蕉是黄的”或者“它还没熟吧”。这个时候输入和输出就不存在这样一种强烈的对应关系,并且背后隐含着的是 Commonsense:“香蕉一般来说是黄的”。这种非对应,和欠缺知识,为我们构建输入和输出的 mapping 带来了困难。
进一步地,我们可以将问题分成两类:
- Shallow NLU,主要就是指的是类似 NMT 这些有着强 Alignment,Mainly Focus on Surface Pattern;
- Deep NLU:类似 Data-to-Text 问题,弱对应关系,并且需要额外的知识的补充才能更好地解决这个问题
所以,为了更好地解决 Deep NLU 问题,我们需要在现有的 Model(主要是 Language Model) 中加入 Knowledge,来缩小 Information Gap。然而,这就又有很多问题摆在眼前,知识从哪来?如何表示知识?如何建模利用知识的过程?
How to Obtain Knowledge
首先,先来大致给知识分个类:
- Encyclopedic Knowledge:百科式的知识,当我们询问美国的总统是谁的时候,维基百科显示一个词条就是一个例子。
- Commonsense Knowledge:常识,这些知识是隐含在我们的日常对话之中的;另外还有像社会规约等等的知识在其中。
对于第一种百科式的知识,有很多工作通过人工构建知识库来获取这一部分的知识,WordNet 也是一个很好的例子,其中包含了很多语言的知识;而对于第二种知识,也有类似的知识库,比如 ConceptNet,是通过搜集网络上人们的看法来对某些概念做一些常识性的推断。但是,人工搜集构建的方式总归是比较麻烦的,而常识信息隐含在对话之中:例如,我们会说“我把石头扔出去了”而不会说“我把大象扔出去了”,这里就包含着着石头比我轻,以及大象比我重这样的物理知识在里面。能不能从语言中抽取出类似这样的物理知识?Verb Physics 就做了这样一个工作。
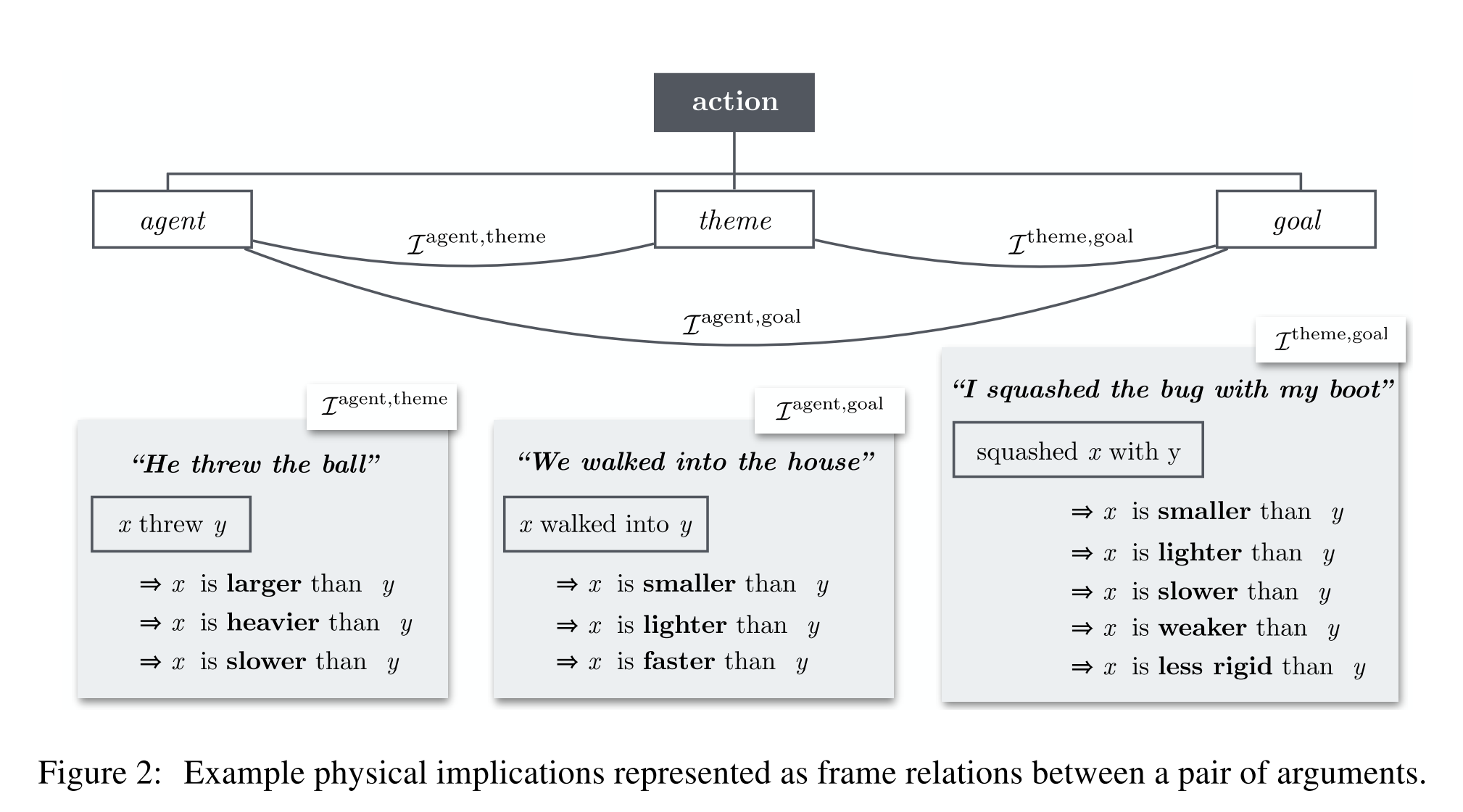
文章主要关注动词以及其相关词组所隐含的物理信息,包括大小(size)、速度(speed)、硬度(rigidness)等,这样我们就可以把这个任务视作是一个分类任务,根据给定的 (x, y, verb) 这样一个三元组,来选择在某个物理属性上 x 和 y 的关系(大于、小于或者约等于)。
另外有两点值得一提,
- 数据集的构建:包括了动词的选取,动词词组(frame)的构建以及跨知识源的知识收集(主要是人类知识作为辅助)
- Model:文章对三种 node 进行建模 frame / verb / object,而其中又因各个 node 之间的联系存在很多的转移边,模型整体比较复杂,建议可以阅读原文来深入地了解。另外,很多的信息他的数据对是比较稀疏的,因此也就需要借助类似的 Pair 来辅助传递,所以还需要考虑到各个 node 之间的联系(相似度)
虽然看起来文章只是在动词所包含的物理信息上做了一些探索,但毫无疑问,如何从非结构化的自然语言中获取知识,并且用于辅助接下来的推理、分析是非常有趣也很有意义的一个方向。
Representation of Knowledge
在有了外部的知识之后,如何来表示这些知识,又是一个值得思考的问题。外部的知识往往可以表示为知识图谱中 (head, relation, tail) 这样的三元组,表明 head 和 tail 之间有着 relation 这样的一条信息,有些时候我们可以忽略掉 relation,比如说某些词的近义词,就可以构成一个 Bag-of-Words 的词袋模型。针对这两种(后一种可以视作是三元组的退化),我所了解到的表示方式有以下几种。
针对 Bag-of-Words
拿着一堆词,我们能够做的事情其实并不多,离散的 word index 并不能携带什么信息,常用的方法有
- Embedding:借鉴 word embedding,我们可以把这些辅助的信息映射到某个低维空间,让 model 自己习得其中的语义关系。之前在一篇 aspect-level review generation 中,作者就尝试将 aspect 信息 map 到一个 embedding 空间,从而让生成评论是关于某个商品的某个层面。这种方法最大的优点就是简单,但是我个人实验的过程中会出现输出的评论欠缺多样性的问题,还有待深入研究。
- Transformation:常用的将词语转换成隐表示的手段在前几年是 RNN,特别是对有时序关系的一组词,丢进 RNN 里把每个 time-step 的 hidden state 作为词语的表示即可,后续再使用 attention mechanism 来利用这些信息。而最近很火热的 Transformer 也完全能够起到这样的作用,如果词之间没有明显的时序关系,也许利用 Self-Attention 能更好地捕获词之间的关联信息,从而得到一个更好的表示。
- Memory Network:记忆网络也是
针对知识图谱
之前提到很多知识库都是基于图来进行表示的,但是直接把知识图谱给塞进神经网络还是比较困难的。我目前接触到的主要手段就是 Graph Convoluctional Network (GCN,图卷积网络),在知识图谱上做卷积操作,得到其表示,从而辅助接下来的任务。Actually,这块我并不是很了解,国内知识图谱以及其表示工作做的比较出色的就是刘知远老师了,感兴趣的读者可以到他的主页了解更多的相关工作。
Integrating Knowledge Into Neural Models
终于,历经千辛万难之后,我们到了最后一个阶段,如何把抽取得到并且有着较好表达能力的知识表示整合进神经网络模型。这里还是围绕 Choi 的两篇工作讨论,而这有两篇工作又都是围绕着菜谱。Choi 在一个 Talk 上表示她非常希望以后早上起床有机器人能给她做早饭,可能她不怎么会做菜吧哈哈哈。
第一篇文章 Checklist Models 说的是菜谱生成,给定原料列表和目标,比如我们要做一道 西红柿炒蛋,原料列表就是 西红柿、鸡蛋 等,生成的菜谱可能就是下面这种:
1、将西红柿洗净后用沸水烫一下,去皮、去蒂,切片待用。
2、将鸡蛋打入碗中,加盐,用筷子充分搅打均匀待用。
3、炒锅放油3汤匙烧热,将鸡蛋放入锅中炒熟盛出待用。
4、将剩余的油烧热,下西红柿片煸炒,放盐、糖炒片刻,倒入鸡蛋翻炒几下出锅即成。
主要的难点在于前后文的连贯性,我们要把西红柿和番茄都得说到,并且可能要重复说,重复说的时候就要考虑到之前对番茄已经处理过了,它的位置都可能发生了变化。模型利用了和类似 MTA-LSTM 中 Coverage 机制,维护一个为使用的原料列表和使用过的原料列表,每次生成菜谱的词的时候会根据当前的 hidden state 来生成一个概率分布,是要利用原料中的词,还是使用过的词还是直接生成词:
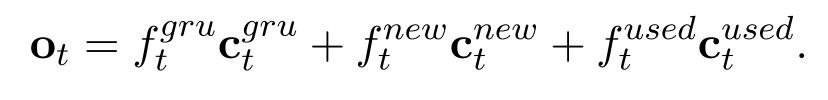
模型示意图如下:
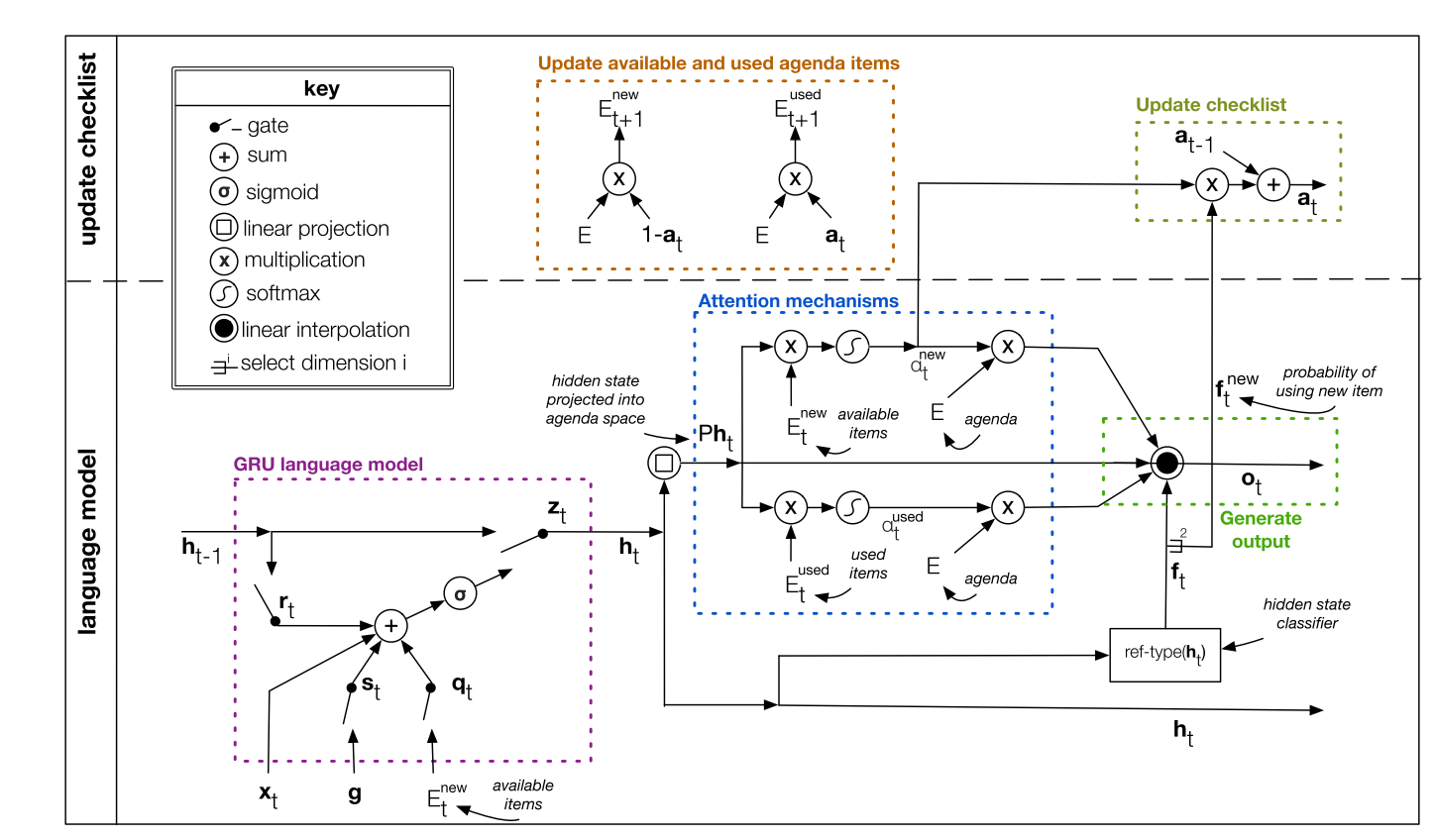
总体来说模型不复杂,核心就是一个 Checklist,这种融合方式是启发式的,模拟人类写作的过程,而这个 Checklist 估计也是从此而来。
另外一篇文章则更多地是围绕着推理,我们在看菜谱的时候,实际上是理解一种过程语言,而过程语言的难点就是会有一些省略的指代,以及实体状态的变化。比如我们不能把鸡蛋直接搅拌,而是要打碎得到蛋液之后才能进行这样的操作。为了模拟阅读菜谱的过程,Choi 等人提出了 Neural Process Model(NPM),模型示意图如下:
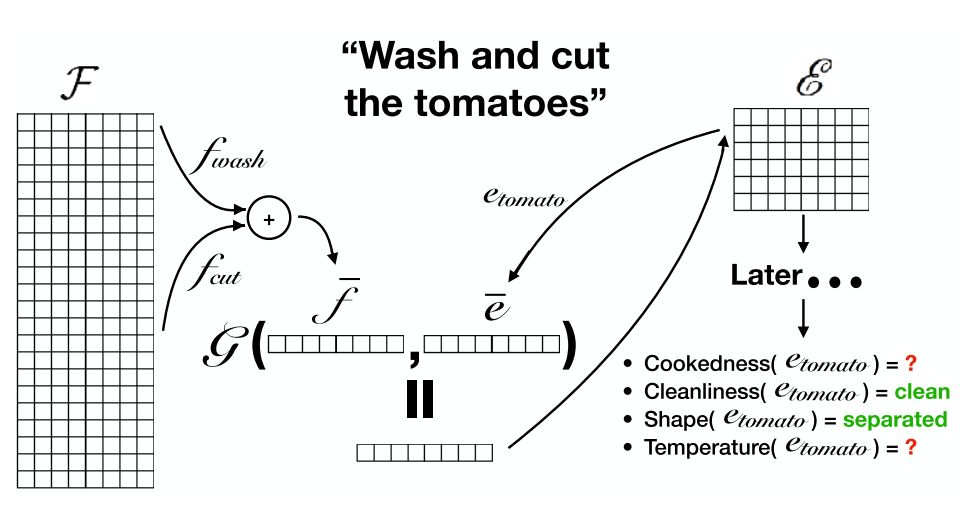
菜谱的两个核心要素是 action(动作)以及 entity(原料实体),那么理解菜谱就可以认为是根据动作来对实体的状态进行改变的一个过程。基于这样一个想法,NPM 从菜谱的每一句中选择需要执行的动作,以及对应的 entity,然后交给一个 applicator 在 entity 上执行操作,从而带来相应的 state embeddings 改变。而这里的实体的状态,作者选取了一些具有代表性的比如:温度(加热之后温度会上升)、位置(把鸡蛋打碎后鸡蛋应该在碗里)。
这几步中最困难的就是选取正确的实体,而仅仅通过 sentence encoding + attention 机制是不够,因为有些时候我们会选择上一句甚至更之前出现的实体,因此,文章借鉴了之前菜谱生成的思路,每次在 hidden state 上做一个三类的分布, 分别是当前的 attention weight / 上一步的 attention weight / 以及不采用,从而将历史的 attention 信息考虑进来:
模型其他的细节就请读者参考原文。文章利用在实体选择上的 F1/ ACC以及状态改变上的 F1/ACC 指标对 model 做了评估,结果也都能超过 baseline。但这篇文章的亮点并不在于取得了 SOTA 的效果,而是在于一种尝试,对于理解过程式语言的一种探索。事实上,现在 NLP Community 的关注点已经逐渐从诸如 NMT 的几个点的 BLEU 值转向让 NLP 系统更加智能的方向。这是一个好事,也许未来不久的某一天,我们就能吃上机器人做的菜了!