
Understanding and Improving Layer Normalization 阅读笔记
LayerNorm 是 Transformer 中的一个重要组件,其放置的位置(Pre-Norm or Post-Norm),对实验结果会有着较大的影响,之前 ICLR 投稿中就提到 Pre-Norm 即使不使用 warm-up 的情况也能够在翻译任务上也能够收敛。所以,理解 LayerNorm 的原理对于优化诸如 Transformer 这样的模型有着重大的意义。先来简单地复习一下 LayerNorm,类似 BatchNorm,其核心思想就是对同一层内的神经元的值进行 Normalization 操作。具体地就是计算输入向量 $\mathbf{x}$ 内各个单元的均值 $\mu$ 以及方差 $\sigma$,然后通过一个学习一个 gain $\mathbf{g}$ 和 bias $\mathbf{b}$ 来 re-scale 回去:
\[\mathbf{h} = \mathbf{g} \odot N(\mathbf{x}) + \mathbf{b}\] \[N(\mathbf{x}) = \frac { \mathbf{x} - \mu}{\sigma}\]那么,为什么 LayerNorm 能帮助模型收敛呢,一个比较普遍的看法就是 LayerNorm 能够使得每一层的输入分布变得更加的稳定(因为进行了 norm 操作),但这是从神经网络前向的角度出发考虑的,LayerNorm 是否从梯度上对网络的训练有所帮助呢?接下来的讨论,将会基于一篇 NeurIPS 2019 上的文章,这篇文章的作者发现了两个有趣的结论:
- LayerNorm 中引入的 gain 和 bias,可能会导致 overfitting,去掉他们能够在很多情况下提升性能
- 和前向的 normalization 相比,norm 操作之中因为均值和方差而引入的梯度在稳定训练中起到了更大的作用
基于此,作者也提出了一种提出自适应学习 gain 和 bias方法,称之为 AdaNorm。文章的贡献就如标题所说,探究了一下 LayerNorm 的原理,然后提出了一种改进的方法。比起方法本身,作者做这个研究的思路更让我喜欢:从现象入手,分析结果并且设计合理的实验来验证想法,最后基于此设计新方法并且辅以适当的理论证明。接下来,就 follow 作者的思路,来一起探究一下 LayerNorm。
Understanding Layer Normalization
LayerNorm 有可能从两个方面起作用
- 正向的 normalization,让输入分布稳定,这里还有一个比较值得研究的就是 rescale 的两个参数 bias 和 gain;
- 在 norm 的计算过程之中,引入的反向的梯度
因此,作者先对比了一下把 gain 和 bias 去掉的实验结果:
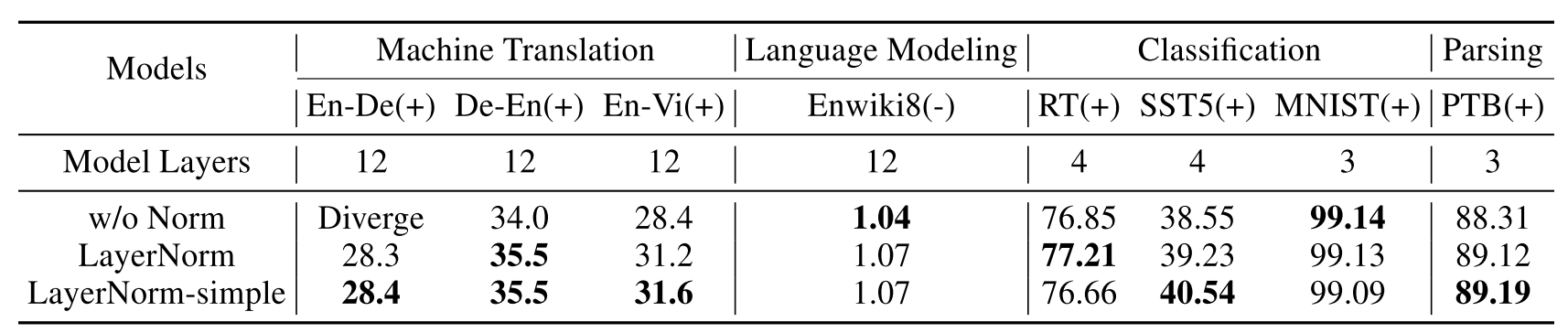
这里有两点发现:LayerNorm 能 work (废话,不然为什么大家都用它);去掉 re-scale 的两个参数(LayerNorm-simple)在很多数据集上都有提点,甚至在 En-Vi 上取得了 sota 的效果。这点有些奇怪,因为原先的设计是很符合直觉的,让神经网络学到这个 re-scale 的参数,但是为什么去掉这个之后反而效果变好了呢?作者把 training loss 曲线打出来一看,诶,simple version 抗过拟合的效果更好。再联想到 gain 和 bias 都是模型在 training set 上直接学出来的,而没有考虑到具体的 input,是非常有可能出现过拟合(即, training 和 test 不匹配)。这个想法很自然,也非常 make sense。我其实很好奇为什么作者会想到把这俩参数去掉,不过我猜测可能是就随手一试?这也告诉我们一点:很多 idea 就是试出来的,勤动手跑跑实验改改 model,说不一定 NeurIPS 就在等着你了。
DetachNorm
接下来我们 focus 到前向 norm 的效果,但是原先的 LayerNorm 中,前向传播中计算 mean 和 variance 的过程会引入梯度的计算,这样就无法分离两个部分的效果。为此,作者提出了 DetachNorm,操作也很简单,就是把梯度给截断掉,用一个 mean 和 variance 的 copy 来进行 norm,用 PyTorch 实现的话就是 Tensor 的一个 detach 方法就能搞定。作者称之为 DetachNorm,用这个方法分别和不用 LayerNorm 以及 LayerNorm-simple 对比,可以对比前向 normalization 以及后向梯度的效果
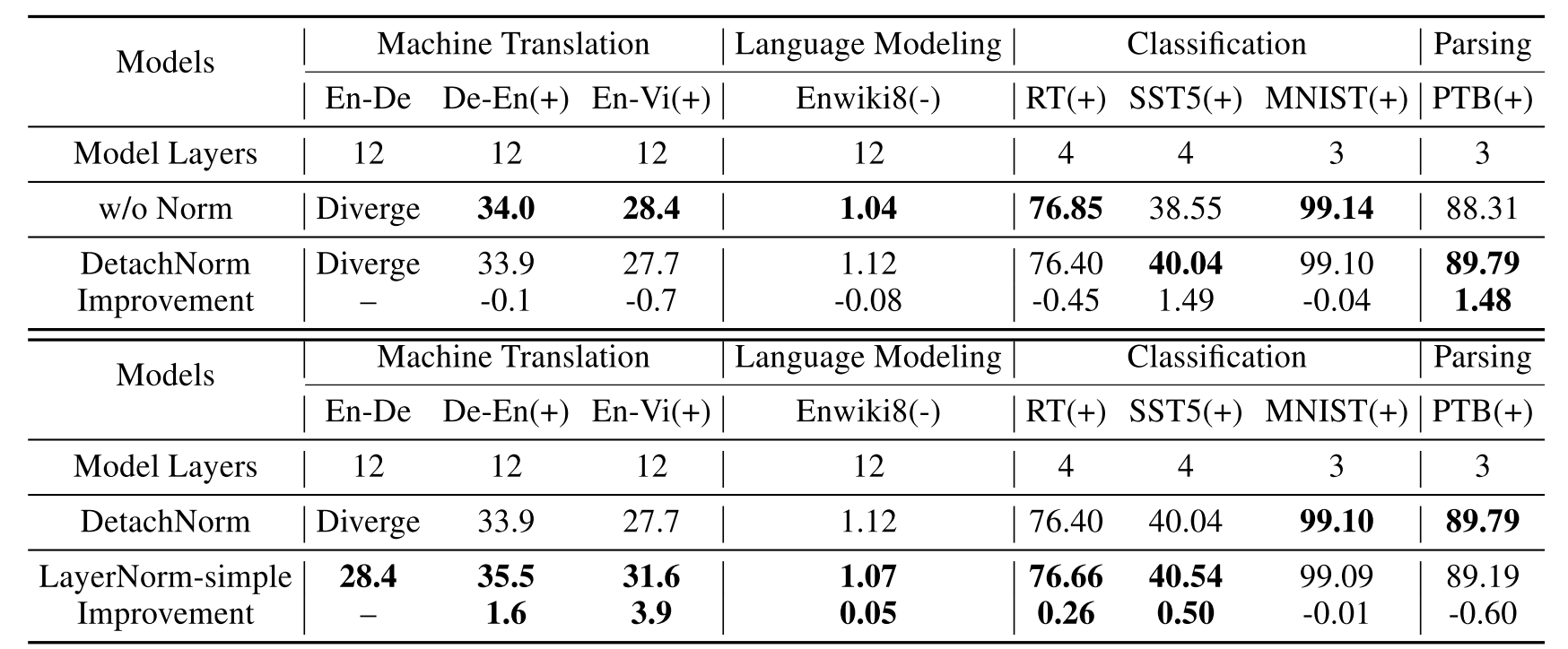
可以看到,仅仅考虑前向 norm 的效果,只在 SST 和 PTB 上取得了性能提升,而引入后向梯度的 LayerNorm-simple,相比 DetachNorm,在多个数据集上都有提升。基于此,作者得出了之前提到的结论:
和前向的 normalization 相比,norm 操作之中因为均值和方差而引入的梯度在稳定训练中起到了更大的作用
那么接下来,很自然的,我们就会关注到后向的梯度之上,这三种方法(LayerNorm / LayerNorm-simple / DetachNorm)上 gain 和 bias 带来的梯度有什么不同呢?作者从理论上证明了:
- $\mu$ :能够让梯度回到 0 附近
- $\sigma$:能够降低梯度的 variance
这二者,被作者称为 gradient normalization。所以总结一下,LayerNorm 起作用的原因:一方面通过使得前向传播的输入分布变得稳定;另外一方面,使得后向的梯度更加稳定。二者相比,梯度带来的效果更加明显一些。
AdaNorm
之前提到,原先的直接学习 gain 和 bias 有可能导致 overfitting 的问题,作者提出的解决方法就是,gain 和 bias 需要将 input 考虑进来,讲新的 Norm 函数设计为:
\[\mathbf{z} = \phi (\mathbf{y}) \odot \mathbf{y}=\phi( N(\mathbf{x}))\odot N(\mathbf{x})\]这里 $\phi(\cdot)$ 的设计需要满足几个要求:
- 可微分,不然梯度没法传递
- 类似原先的 rescale 操作中 $\sigma$,我们希望$\phi(\mathbf{y})$ 需要是一个常量,并且大于零
- 得到的输出 $\mathbf{z}$ 的均值应该是有界的,来避免 loss 爆炸
最终,作者将 $\phi(\cdot)$ 定义为,并且证明其满足以上的三个要求:
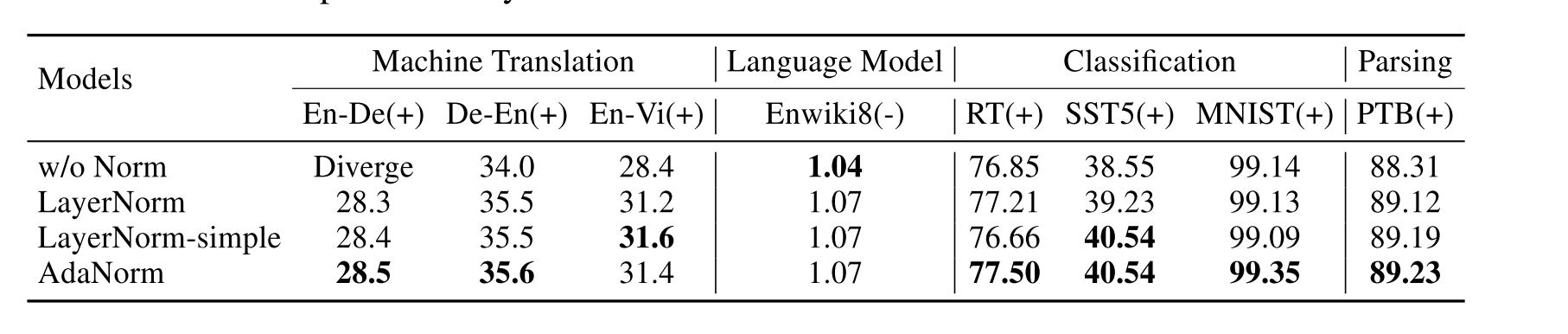
\[\phi(y\_i) = C(1 - k y\_i)\]实验的结果也令人满意,在多个数据集上都超过了 LayerNorm-simple:
Summary
如我开头所说,AdaNorm 方法本身并不是这篇文章的主要亮点,我更为欣赏的而在于作者整个探究的思路,希望能够学习这种做研究的方法:
- 切入的角度:选取一个大家都在用,但是又不怎么清楚的 block 来进行探究。我觉得今后做研究的思路就是要考虑实际的价值和应用的场景,而不单单是为了创新而创新,思考不考虑能否对整个社区做出贡献。
- 由表及里,从现象到本质:在选定好方向之后,多多尝试,多跑几组实验,改改这里改改那里,从现象中总结出规律,尝试用基础的原理来解释现象,而不是对着某个指标一顿调参而不深究。
- 有的放矢:发现问题之后,针对性地提出解决方案,做到有的放矢。
希望大家也能早日做出让自己满意的工作!