
Actor-Critic - A improvement of Policy Gradient
Improvement of Policy Gradient
上篇 Blog 中讲到,我们对于 Agent 参数的更新是基于 reward function 对最大似然 loss 加权得到的 Objective Function,这里有两个问题:
- reward function 需要在完整的一次 trajectory 后才能够计算,也就是说,是回合更新的。这样更新的频率更新就比较慢,相应地,训练就会缓慢一些。
- 因为每次我们都是在当前的一个回合上计算 reward,但每次回合 Agent 所采取的策略都会有所不同,这样子就会导致我们的方差(variance)比较大。
对于第一个问题,我们的解决方法是,根据每个 Agent 的每次 Action 进行参数的更新,也就是我们接下来要说的 Actor-Critic;第二个问题,也就是我们最好能够对所有的样本进行估计来计算我们的 reward(也就是 reward 的数学期望),以此来降低方差。
具体地,我们可以采取以下几种 reward function:

图源自知乎,详见 Reference
第一种也就是最为普通的 reward function,各步的累加;第二种则是不考虑先前步的 reward,这里有一个 casualty 的性质,即今天的参数更新是无法影响昨天以及之前获得的 reward的,因而可以只考虑今天之后的 reward;第三种则是加入了 baseline,在基准之上衡量 reward,能够更好地指示动作的好坏,基准一般会采取所有回合的 reward 均值。值得强调的是,这三种方式都是对 reward 的无偏估计 (unbiased),但天上不会掉馅饼,尽管第二种第三种方式对第一种方式修改后 variance 有所降低,但整体的方差还是比较大的。
而后面三种,则是希望通过再用一个 NN,来评估当前的状态能够获得 reward。这样的估计,必然是 biased 的,因为这个 NN 基本不可能是 Perfect 的;当然,这样做的好处就能够降低 variance,所以这是一个 trade off 的问题,后面三种的详细式子如下:

Q 是对当前状态 $s_t$和采取的动作$a_t$能够获得的 reward 进行估计;而 V 仅仅考虑对状态 $s_t$ 能获得的 reward,也就是对于所有 $a_t$ 的 Q 的数学期望;A 又称 Advantage Function,是衡量 $a_t$ 好坏的一个指标,从 $ A= Q-V$ 就能看出来。那么问题来了,这三个函数彼此相互关联,我们用 Neural Network(NN) 来拟合哪一个呢?
答案其实也已经在上面的那种图里了,通过一些约等式,我们能够通过拟合 $V^{\pi}(s)$ 来得到 Advantage Function,实际应用中主要就是采取 Advantage Function 作为对当前所采取动作的评估函数。
Actor Critic Network
上面的 Advantage Function 起到的作用类似一个教练(或者说是批评家),对于我们的 Actor 当前的状态和采取的动作做出指示,帮助他更好的达到目标,这也就是 Actor-Critic 算法的名字由来。我个人对 AC 算法的认识就是基于对 Policy Gradient 的优化而得到的,Actor 就是我们之前谈到的 Policy,其核心就在于用 NN 来扮演这个 Critic 的角色。
既然是 NN fit V function,那么训练集是什么呢?即我们如何根据当前的状态,来估计整个回合获得的 reward呢?这里有两种做法:
- Monte Carlo evaluation:蒙特卡洛搜索,就是对未来可能采取的动作进行搜索,计算获得的 reward
- 通过 V 本身来计算,获得的 reward 等于当前这一动作能获得的 r 和下一状态用 V 估计值之和,即 $ reward = r(s_t, a_t) + V (s_{t+1})$
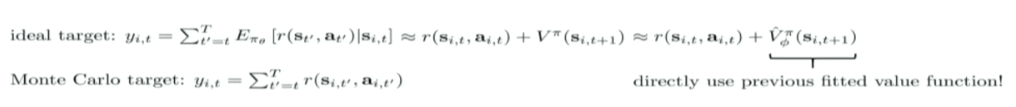
一般我们都会采用第二种方法,也称为 bootstrapped estimate,由此,我们就可以构造出相应的 training data,用 NN 解决一个 regression 问题:
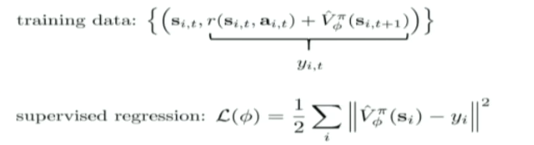
Program
又到了喜闻乐见的代码实现部分,其实也简单,两个 NN 嘛,有点 GAN 的感觉。实际上,有论文将 Actor 和 Critic 两个 NN 整合成一个 NN,并且做出了不错的效果,好处就是能够共享特征(shared features),不好的地方就是,训练可能不是很稳定。这次就不贴完整代码,上一篇 Blog 和这篇以及后续 RL 相关的代码都会上传到 GitHub 上,这里只讲解部分核心的函数。
|
|
训练部分,和 Policy Gradient 大同小异:
|
|
最后,我们来看一下结果:
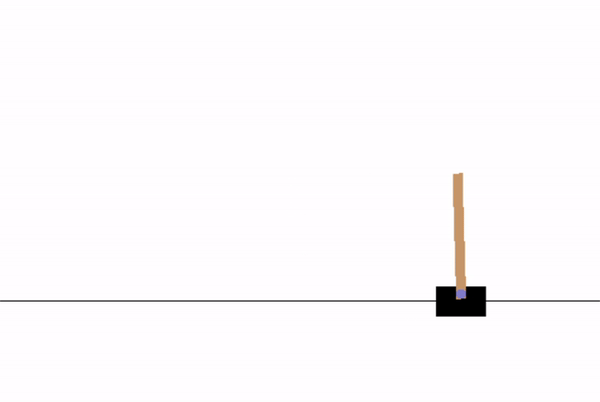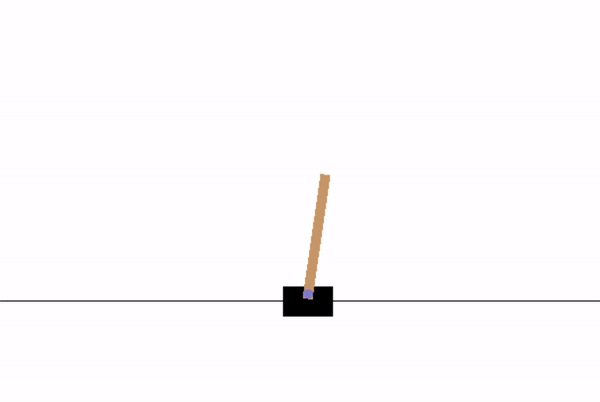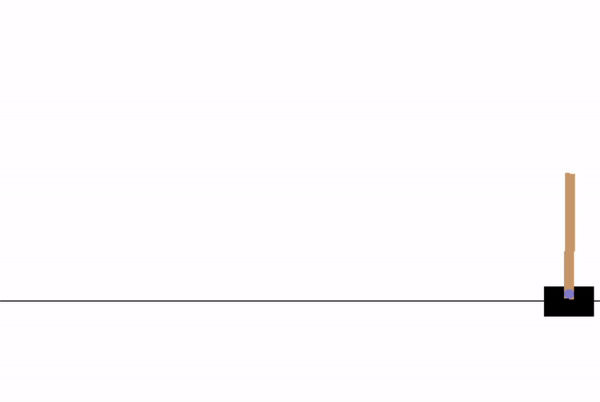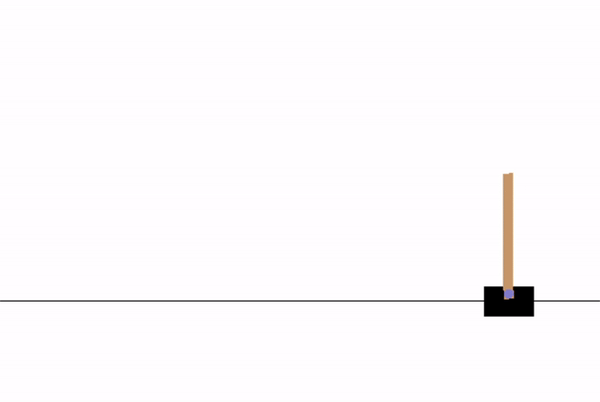
一个很有趣的现象就是,第一次玩出界了,第二次能够在快出界的时候纠偏回来,性能确实比简单的 Policy Gradient 好很多。不过,这个训练似乎并不收敛,跑了 200 epoch 之后又会因为一次错误的尝试而导致后面一系列的错误… 果不其然是玄学啊。