Text Generation 是我非常感兴趣的一个问题,传统的 Seq2Seq 能有不错的效果,但如前一篇 Blog 所说,我相信未来的文本生成必然是与 GAN 以及 Reinforcement Learning (RL)相结合的,上交的大佬 Lantao Yu 就有一篇很出色的 SeqGAN 的工作,以及最近的 MaskGAN。接下来的一段时间,尝试实现 SeqGAN 和 MaskGAN,根据需要学习相关的 RL 知识。这篇 Blog 就算是一个前哨,主要讲简单的 Policy Gradient。
Brief Introduction of RL
强化学习是一类机器学习算法的统称,其核心思想是让计算机通过尝试,学会特定行为模式以达到期望目标。前一阵子大火的 AlphaGo 以及各类打游戏的 AI 都是强化学习的产物。强化学习中把计算机程序抽象成一个 Agent(Policy),其所处的环境抽象为 Environment,学习就发生在 Agent 和 Environment 的不断交互之中,示意图如下。
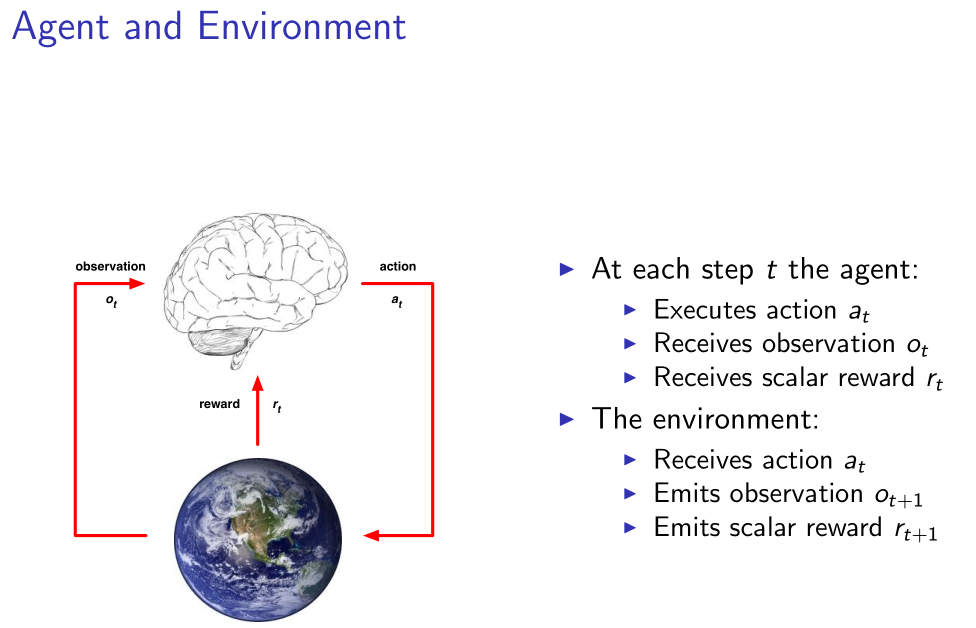
还有一个重要的概念叫做 state,是关于我们所获知的发生的一切(过去所有的 observation,采取的 action,和获得的 reward) 的函数,在一个观测完全(fully observed)的环境中,我们可以认为 agent 的 state 和环境的 observation 是一样的。事实上,我们需要的 Policy,就是一个 state -> action 的映射。而 Deep Reinforcement Learning,就是通过深层 NN 来构建这个映射。
强化学习算法一般为两类:
- Model - free Approach
- Model- based Approach
这里的 Model 指的是环境,Model-free 算法不需要对环境进行建模,Policy 通过环境的 reward (奖赏)来指导学习;而 Model-based 类算法则有着对环境的建模,我们可以利用这个 Model 来搜索预判可能发生的情况,并据此为 Policy 选择行动策略。
Deep Policy Gradient
Policy Gradient 是一类很重要的 RL 算法,其核心步骤如下:

我们用 u 来控制 NN 的参数,并且通过 SGD 来更新这个 u,使得能够获得更多 reward 的 action 能够更可能被采纳。因为 reward 是随时间步而累积的,我们通过一个 discount factor $\gamma$ ,来控制 reward 的衰减,避免出现无限的情况。如果我们用 $x$ 来表示一次完整的行动(trajectory),$f(x)$ 来表示 total reward function, $p(x)$ 表示我们的 Policy ,$\theta$ 表示控制 NN 的参数。那么我们的目标就是让 reward function 的数学期望最大,SGD 更新,则使数学期望对求导过程如下:
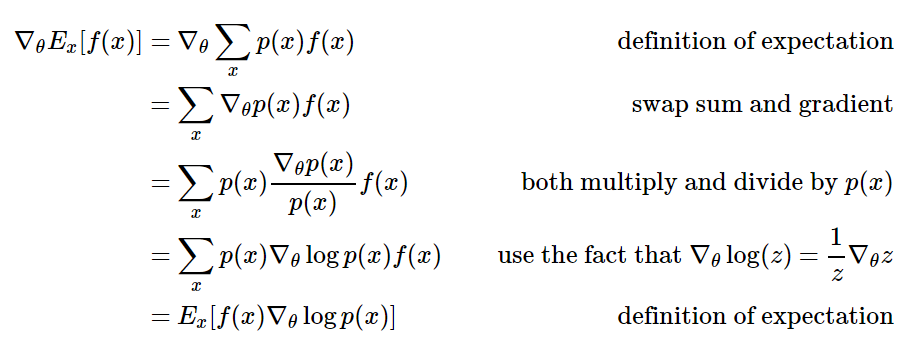
注意,$f(x)$ 和 $\theta$ 是无关的 ,也就是说,我们只要求 $log\ p(x)$ 对 $\theta $ 的导数,再乘上 reward function 就可以了。实际实现中,我们肯定是不求数学期望而是采样 N 个 samples 然后求平均,和最大似然的方法相比,发现只需要在 Objective Function(这里的函数称为 loss 有一些不合适) 上乘上一个由 reward 进行加权的函数即可:

Program
数学之后,就是编程实现了。OpenAI 提供了一个用于训练强化学习的库 gym,提供了一些接口,非常可以通过传递 action 来得到对应的 state 和 reward,并且里面有很多游戏,可以拿来让我们的 agent 学着玩。这里我们拿 CartPole 游戏做测试,游戏的玩法如下所示:
游戏的目标就是保持一根杆子一直竖直向上,杆子会因为重力而摆动。允许摆动范围是 -15° ~ 15°,并且左右移动也有一个限制,不能移过头,否则就是 Game Over。使用 gym 接口的代码如下:
1
2
3
4
5
6
7
8
9
10
|
import gym
env = gym.make("CartPole-v0")
env.seed(1) # 设置随机数种子 方便调试
env = env.unwrapped
print(env.action_space) # 输出 Discrete(2,)
print(env.observation_space) # 输出 Box(4,)
observation, reward, done, info = env.step(action) #
|
可以看到,我们的 action 有两个选择:向左;向右; observation 则是一个 4 维向量,猜测是杆子两个端点的坐标。另外,我们可以通过 env.step(action) 来执行一步操作,并且获得对应的返回值。第三个 done 是指示游戏是否 Over 的量,如果为 True 就说明游戏结束了。
gym 接口的使用就这些,接下来就要搓一个 Agent 来玩游戏了。
1
2
3
4
5
6
7
8
9
10
|
import numpy as np
import tensorflow as tf
class PolicyGradient:
def __init__(self):
def _build_net(self):
def choose_action(self, observation):
def store_transition(self, s, a, r):
def _discount_and_norm_reward(self):
def learn(self):
|
一个一个函数来吧,首先是这个类的构造函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
def __init__(self,
n_actions,
n_features,
lr=0.01,
reward_decay=0.95,
output_graph=False):
self.n_actions = n_actions
self.n_features = n_features
self.lr = lr
self.gamma = reward_decay
self.sess = tf.Session()
self.ep_obs, self.ep_as, self.ep_rs = [], [], []
self._build_net() # 构建网络
self.sess.run(tf.global_variables_initializer())
|
我们传入一些训练的参数,包括 action 的数目,以及 observation 的 feature,对于CartPole,就是 2 和 4。还有就是 discount factor,以及学习率 lr。最后两行,我们构建了一个网络并且对变量进行初始化。
然后就是最核心却也非常简单的 net:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
def _build_net(self):
# input
with tf.name_scope('inputs'):
self.tf_obs = tf.placeholder(tf.float32, [None, self.n_features]) #
self.tf_acts = tf.placeholder(tf.int32, [None, ], name='actions_num')
self.tf_vt = tf.placeholder(tf.float32, [None, ], name="action_valuie")
# fc1
layer = tf.layers.dense(inputs=self.tf_obs,
units=10,
activation=tf.nn.tanh,
kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.3),
bias_initializer=tf.constant_initializer(0.1),
name = 'fc1')
# fc2
all_act = tf.layers.dense(
inputs=layer,
units=self.n_actions,
activation=None,
kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.3),
bias_initializer=tf.constant_initializer(0.1),
name='fc2')
self.all_act_prob = tf.nn.softmax(all_act, name='act_prob')
with tf.name_scope("loss"):
# to maximize total reward log p * R = minimize - log_p *R
neg_log_prob = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=all_act, labels=self.tf_acts)
loss = tf.reduce_mean(neg_log_prob * self.tf_vt)
with tf.name_scope("train"):
self.train_op = tf.train.AdamOptimizer(self.lr).minimize(loss)
|
熟悉神经网络模型的话就知道实质上我们就是用了两层全连接层,最后输出一个 Action 的概率;这里的 loss 就是我们的 Objective Function,先是一个 cross_entropy,然后再通过 tf_vt ,也就是我们的 reward 进行加权求和。
1
2
3
4
5
6
|
def choose_action(self, observation):
prob_weights = self.sess.run(self.all_act_prob, feed_dict={
self.tf_obs: observation[np.newaxis, :]
})
action = np.random.choice(range(prob_weights.shape[1]), p=prob_weights.ravel()) # selction action w.r.t the actions prob
return action
|
第三个函数,这里和平常的直接 argmax 作为输出不一样,而是根据我们的输出的概率进行 random 选择动作。第四个函数 store_trainsition(),对我们一次游戏中的各个 state 进行保存:
1
2
3
4
|
def store_transition(self, s, a, r):
self.ep_as.append(a)
self.ep_rs.append(r)
self.ep_obs.append(s)
|
然后是计算我们的 reward:
1
2
3
4
5
6
7
8
9
10
11
|
def _discount_and_norm_reward(self): # reward decay and normalize
discount_ep_rs = np.zeros_like(self.ep_rs)
running_add = 0
for t in reversed(range(0, len(self.ep_rs))):
running_add = running_add * self.gamma + self.ep_rs[t]
discount_ep_rs[t] = running_add
# normalize episode rewards
discount_ep_rs -= np.mean(discount_ep_rs)
discount_ep_rs /= np.std(discount_ep_rs)
return discount_ep_rs
|
我们取出一次游戏的每一步的 reward 并且计算经过衰减的 reward,并且做一次 normalize(PS:不做 normalize 操作的话学习的很慢,也反应了 RL 训练其实是很 tricky 的)。
最后,根据我们的 reward,我们对 agent 的网络进行一次更新,再一次强调,这个更新的目的是让能获得更高奖赏的动作出现的概率增大,让 bad choice 的概率变小:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
def learn(self):
discount_ep_rs_norm = self._discount_and_norm_reward()
# train on episode
self.sess.run(
self.train_op, feed_dict= {
self.tf_obs: np.vstack(self.ep_obs), # [None, n_obs]
self.tf_acts: np.array(self.ep_as), # [None, ]
self.tf_vt: discount_ep_rs_norm
}
)
self.ep_obs.clear()
self.ep_rs.clear()
self.ep_as.clear()
return discount_ep_rs_norm
|
好了,我们的 Agent 已经写完了,接下来就是让他边玩边学:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
threshold = 400 # 展示阈值
render = False # 是否展示 bool
RL = PolicyGradient( # 实例化一个 Agent
n_actions = env.action_space.n,
n_features = env.observation_space.shape[0],
lr= 0.01,
reward_decay = 0.99
)
for i in range(1000): # 玩 1000 次
observation = env.reset() # 重置游戏
while True:
if render: env.render() # 如果超过阈值 那么就展示玩的过程
action = RL.choose_action(observation) # 让 agent 根据 Observation 选择 action
observation_, reward, done, info = env.step(action) # 执行一步 Action
RL.store_transition(observation, action, reward) # 储存状态
if done: # 如果 game over 我们进行一次更新
ep_rs_sum = sum(RL.ep_rs)
if 'running_reward' not in globals():
running_reward = ep_rs_sum
else:
running_reward = running_reward * 0.99 + ep_rs_sum
if running_reward > threshold:
render = True # rendering
print("episode:", i, " reward:", int(running_reward))
vt = RL.learn() # 更新
break
observation = observation_ # 更新 observation
|
大功告成,跑一个试试?
哈哈哈哈其实结果早就放出来了,那个游戏示意图就是大概迭代了 50 次之后电脑自己玩的结果。
Summary
事实上 RL 还是有很多缺点,比如训练 tricky,对样本量需求巨大,这个游戏因为简单所以没有体现出来;以及 Policy Gradient 也存在着一些问题,同时也有对应解决的方案。囿于篇幅,和我们最终的目标是文本生成,就不做深入的讨论,以后有需要再细细研究。我觉得兴趣驱动,任务驱动,自上而下,用什么学什么的方法是最好的。
Reference
Deep Reinforcement Learning: Pong from Pixels
Deep Reinforcement Learning Tutorial
CS294 Fall 2017
莫烦强化学习教程
