
Adversarial Training Methods For Semi-Supervised Text Classification 阅读笔记
这篇 ICLR 2017 刚出的 Paper,这篇 blog 主要记录阅读过程中的一些想法,如有错误之处,欢迎联系指正。
Idea
We extend adversarial and virtual adversarial training to the text domain by applying perturbations to the word embeddings in a recurrent neural network rather than to the original input itself.
如 Paper 的摘要所说,这篇论文的核心思想就是:在 word embedding 上增加扰动(perturbation),来增强模型的鲁棒性,从而提升分类器的准确率。
我对这一点理解是这样的:一段文本,在计算机的处理过程中通常是用一组 词 id 向量来表示的,两个词的 id 是无法体现词之间的关系的,比如 “Good” 和 “Nice”,两个单词是近义词,但是他们的 id 可能隔了十万八千里;而在图像中,也就是 RGB 值的分布,两个相近的颜色的 RGB 值就会非常接近。

我们可以在调色板上随意拖动,颜色就会连续的变化。
在文本领域则没有这样的性质,这就使得这个扰动非常难以定义,作者提出在 word embedding 层添加扰动,而不是在 input 层(图像处理就会在输入的图片上增加 noise 来达到扰动的目的),我觉得是非常聪明的。因为 word embedding 之后,词向量所在的空间可以近似地看成连续的:相同含义(甚至是不同含义)的词在 embedding 后的分布非常接近,增加一点点扰动,可能就能够恰好落在另一个同义词上或者是反义词上。
比如我们在做 Sentiment Classification 的任务,“我觉得这道菜很美味”和“我觉得这道菜很难吃”这两个句子唯一的不同就是最后的形容词,但是 sentiment 就是 positive 和 negative 两个标签,而“美味”和“难吃”在 word embedding 之后很有可能是非常相似的(直觉感受,没有验证)。我们增加扰动使得原来的“美味”变成“难吃”,如果 model 不能正确分类,就说明这个扰动(或者说 adversarial example,对抗样本)是 model 所不能够很好地适应的.文章里添加一个 adversarial loss,来衡量 model 对于扰动的适应能力,通过 minimize 这个 loss,来增强 model 对于对抗样本的能力,最终提升整体分类的准确率。
Model
Adversarial Training

这个例子我觉得非常形象地说明了 Adversarial Example,原本分类器比较自信(57%)地认为图片中是一直熊猫,但在给图片增加人眼都无法分辨的噪点之后,分类器却几乎肯定(99%)地认为图中是一只长臂猿。
那如何衡量模型对 Adversarial Example 的适应能力呢?可以额外定义一个 Cost Function:

Paper 中,将上式 (adv_loss) 和原先分类器的 loss(cl_loss) 相加得到一个新的 total_loss,在训练过程中 minimize 这个 total_loss,就能够实现“Train classifier to be robust to the worst perturbation”的目的了。
Worst Case Perturbation
怎么样的扰动是 worst 的呢?我们称之为 radv,worst 意味着模型最无法 fit ,也就意味它会使 adv_loss 最大,也就是满足下面这个式子:
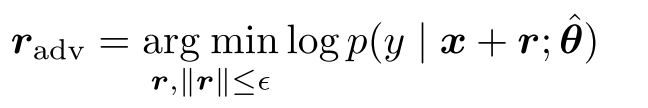
但是因为在神经网络中这个 r 不可微分,所以我们采用一个替代的方案来近似计算 radv:
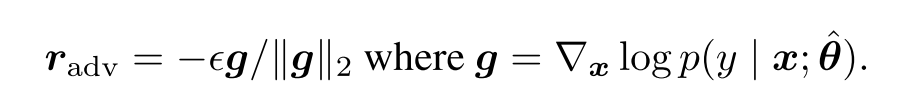
也就是我们计算一个 loss function 对输入 x —也就是经过 word embedding 后的句子向量—的梯度,乘一个负号和 eplison,再除上梯度的 L2 范数即可。
这个方法是大牛 Goodfellow 提出来的(文章还有待阅读),我的理解是这样的:
梯度方向是 loss 下降最快的方向,那么梯度的反向(负号),也就是 loss 上升最快的方向,换而言之,就是我们模型最害怕、最不能适应的一个方向。再经过除以 L2 范数,相当于得到一个单位向量,乘以 epsilon(我们可以通过它来控制扰动的大小),得到我们模型最害怕的一个扰动,也就是 radv。
Virtual Adversarial Training
前面的所提及的都是 Supevised-Learning 情况下的(loss 函数的设置),事实上文本领域还存在大量没有 label 的数据,能不能把这个方法迁移到 Semi-Supervised 情况下呢?答案是:Yes。
没有 label 的情况下,我们通过衡量扰动前后分布的 KL Divergence 来确定 radv:
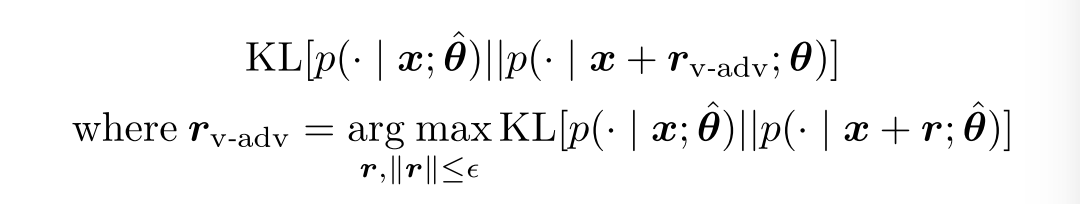
用类似的方法来近似计算 radv:
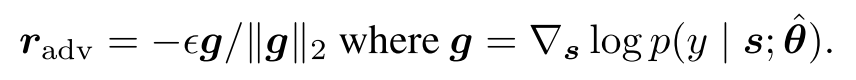
但因为是 Semi-Supervised Learning,不是所有的样本都有 label,所以 loss 的定义也和普通的不同,因为我主要关注 Supervised Learning,所以这一部分没有细读,有待日后补充。
Implementation
Paper 实现的代码 Google 已经开源在 GitHub 了,我把核心的框架提出来,基于原本的 Attention-based Bi-LSTM 来做的,主要在以下几个地方做了改动:
Word Normalization
Paper 中为了避免最后数学上的病态解,于是对 word embedding 做了一个 Normalization:
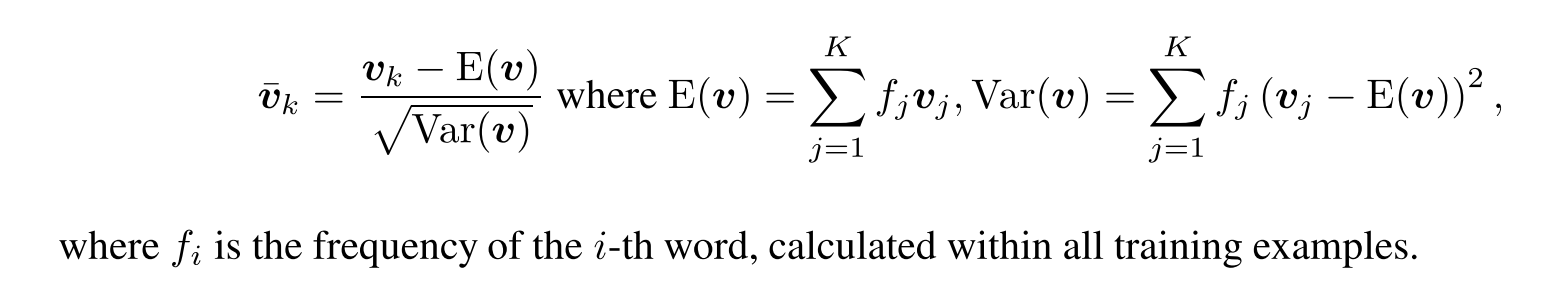
在代码里的实现如下:
|
|
因为我是随着模型一起训练 word embedding 的,没有 pretrain,所以在每次训练中都要对 embedding 做一次 normalization。
Add Perturabation
|
|
我们通过计算梯度(Google 的代码这里没有乘以 -1 作为反向?),在通过 scale_l2 进行对梯度进行求单位向量再乘以 epsilon 得到扰动, scale_l2 就是一个数值稳定(避免 0 为除数)的放缩函数。
Loss
loss = ad_loss + cl_loss:我们先把未增加扰动的 word embedding 交给 Bi-LSTM 得到一组 logits,计算 cl_loss;再将增加扰动后的 embedding_perturbated 交给 Bi-LSTM 得到另一组 logits,计算 ad_loss。二者相加得到我们需要优化的 total_loss:
|
|
Result
因为计算量特别大(计算梯度),所以一开始只用了 1/5 的数据,但也花了 7 个小时,足足是无扰动情况的 20 倍(20分钟)。可能实现上还有一些问题,但是在相同参数和训练步数(大约 5 个 epoch)情况下,Adversarial Trainning 的准确率确实高了 1%(95.69 % 和 94.59 %)。
随后我用 AWS 租了一个 p2 instance( Tesla K80 11G) 来跑全部的数据集,同样是 5 个 epoch 的情况下达到了 98.5%的准确率(接近 2 hours),比 ABBLSTM (i7 1 hour) 高了 0.2 %,效果有,但是很小。
Analysis
我觉得表现不是非常好的原因如下:
- 精度没有达到 Paper 提出的 99.3%,可能是训练次数不够,仅仅是 5 个 epoch(Update: 训练 50个 epoch 也是 98.5% 排除这个原因)
- 没有预先训练 embedding,而是和 Bi-LSTM 一起训练,每次都要重新进行 Normalization,训练速度慢,而且 Adversarial Example 对于 embedding 的依赖很大 所以导致效果也可能不是显著。
- 没有采用文章所采用的一些 Training 的 Trick,比如 gradient clip,loss 退火等
- 超参数没有经过 fine-tuning,比如 epsilon 选的是适合 IMDB dataset 的值,对于 DBpedia 还需要调整。