
GAN 学习笔记
Generative Adversarial Networks,简称 GAN,中文叫做生成式对抗网络,是现在非常火热的神经网络模型。网上关于 GAN 的 Demo 很多,讲解也很多,但都只是在 Intuition 层面的理解,很少涉及其中的数学细节,而我在阅读 Goodfellow 的论文时对其中的公式感到一头雾水,好在最终找到了国立台湾大学的李宏毅老师的公开课视频,这篇文章就是他深度学习课程 GAN 部分的学习笔记。
Intuition
GAN 主要由两个模块组成,Generator(G) 和 Discriminator(D)。有个很形象的比喻就是,G 是一个造假币的,D 是一个验钞机。G 的目的就是要让 D 无法辨别自己的造出的假币,因此 G 就要不断提升自己造假币的技术,尽可能地以假乱真;而 D 自然不能轻易地让 G 得逞,于是也要不断地提升自己鉴别假钞的能力。两方这样对抗式地提升着自己,最终我们就能够得到一个造假币技术很强的 G,这就能可以应用在很多领域之中,比如图像生成,我们就能够生成逼真到足以欺骗人眼的图片,这么好的效果也难怪 GAN 如此火热了。实现的方式也很简单,我们用 NN 来做我们的 Generator 和 Discriminator(Discriminator 其实是一个 Binary Classifier),然后把他们接起来(即把 Generator 产生的 data 作为 input 交给 Discriminator),再利用 Gradient Descent 的方法来训练,就可以达到我们想要的结果了。关于 Intuition 的部分就写这么多,接下来就带着这种理解进入到数学的部分啦。
Basic Idea Of GAN
Maximum Likelihood Estimation

Generator 实际在做的事情就是,对于给定样本分布 Pdata(x),我们希望的我们 PG(x;θ),能够尽可能地接近 Pdata(x),这里的 θ 就是控制 G 的参数,如果是神经网络的话,对应就是各层的 Weights。衡量接近的指标就是上面的 L,其含义就是如果我们从 Pdata(x) 中 采样 m 个 x_i,那么在给定 θ 的情况下,我们可以计算出从 PG 中 采样出 x_i 的几率,将它们连乘得到 L。我们的目的就是找到一个 θ_star,使得 L 能够最大。

上面就是求解 θ_star 的过程,运用了一系列数学的技巧:
- 先取 log 将连乘转化成连加,其结果约等于从 Pdata 中采样 x,再计算其 log 之和(其中 Ex~Pdata 的含义是从 Pdata 中采样 x)
- 把求期望值改成取遍所有 x,转化成一个积分问题
- 接下来再非常有技巧地(我个人看来)在后面减去一项只跟 Pdata有关而与 θ 无关(不影响结果)的积分,再将被积函数中的 log 部分相减得到一个式子
- 最后再将 log 部分上下颠倒,变成最小化问题,其最小化的目标就是 Pdata 和 PG 的KL Divergence,KL Divergence 是用来衡量两个分布的相似程度的指标
General PG —— Nerual Networks

如果我们的分布 PG 是一个很普通的分布函数比如说高斯分布,那他不可能接近现实生活中如此丰富的数据的分布。而 GAN 带给我们非常重要的一个 idea 就是我们可以利用 NN( Nerual Networks) 来作为 PG。因为理论上只要 NN 足够复杂,他是可以拟合任何函数的。在这里 NN 的输入是一个低维的 vector,如果这个 vector 是来自一个 distribution 的话,那么 NN 的输出也可以看做是一个 distribution,这样理论上我们可以通过控制 NN 的 weights,来产生任何分布了。我曾经在看 Demo 代码时对于 G 的输入是一个随机分布非常不解,现在有种醍醐灌顶之感。
利用 NN 来做 PG,它的表示就如上图所示,其中 Pprior 是一个先验分布,就是我们的随机分布 z 的分布(比如是一个高斯分布),再乘上一个 Identify 函数(如果 G(z)=x 则为 1,否则为 0)。
但是这又带来了一个问题,L 现在变得非常难以计算,这样我们怎么才能通过调整 θ 来得到我们想要的 G呢,GAN 的重大贡献就在于提出了这个问题的解决方法:引入 Discriminator。
V (G, D) 的优化问题

这里首先需要找到 D_star 使得 V(G, D) 最大,再在给定 D_star 的条件下,找到 G_star 使得 V(G, D) 最小。

V(G, D) 的定义:
V = Ex~Pdata[log D(x)] + Ex~PG[log (1-D(x))]
利用同样的技巧将求期望转化为求积分,如果假定 D(x) 可以取任意值,那么我们要求解 D_star 使得 V(G, D) 最大,只要使被积函数最大即可。
此时,Pdata(x) 是给定的分布,我们可以用 a 来表示,同理,对于给定的 G,我们可以用 b 来表示 PG(x),求导解得驻点:
D_star = a / a + b
接下来把求得的 D_star 带入 V(G, D),并且做一些数学上的变换(分子分母同时除以2,再拿出 log 1/2),得到结果:
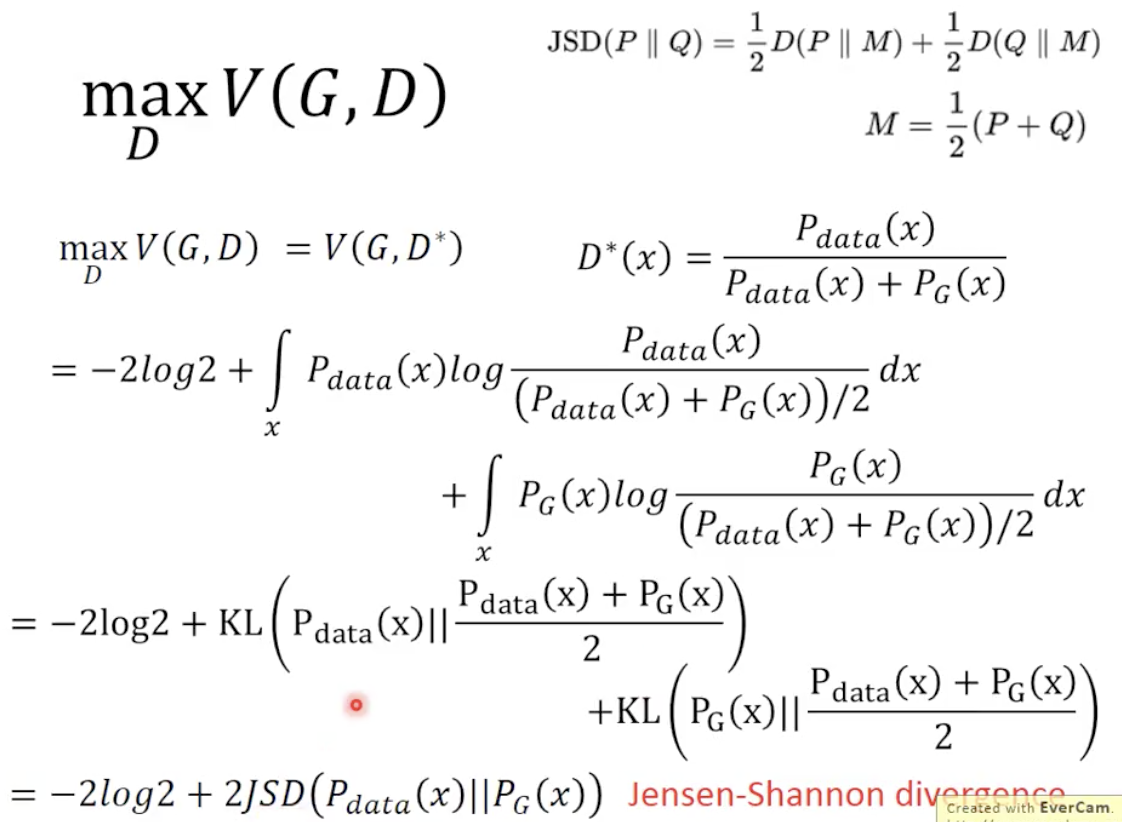
JSD 指的是 Jensen–Shannon divergence,同样是衡量分布相似程度的一个指标
也就是说在这种 V 的定义下,我们其实是在求他们的 JSD,JSD 在两个 distribution 完全没有交集的时候等于 log 2,而在完全相同的时候等于 0,也就是说 :
Vmax = 0 Vmin = -log 4
那我们要找一个 G_star 使得 V 最小,也就是要让:
PG(x) = Pdata(x)
这里就达到了我们一开始说的造假币来以假乱真的目的了,我们的 Generator 产生的 distribution 和真实 data 的 distribution 完全一致。
那么怎么解 G_star 呢?如果我们把 max V(G, D) 这一部分看成是 L(G),那么要使得 L(G)最小,就用Gradient Descent !不过还有一个小问题,就是我们的函数中存在 max,如何求梯度呢?这个不难解决:分段函数,落在哪段函数区间则用哪段区间的微分就行。
Algorithm
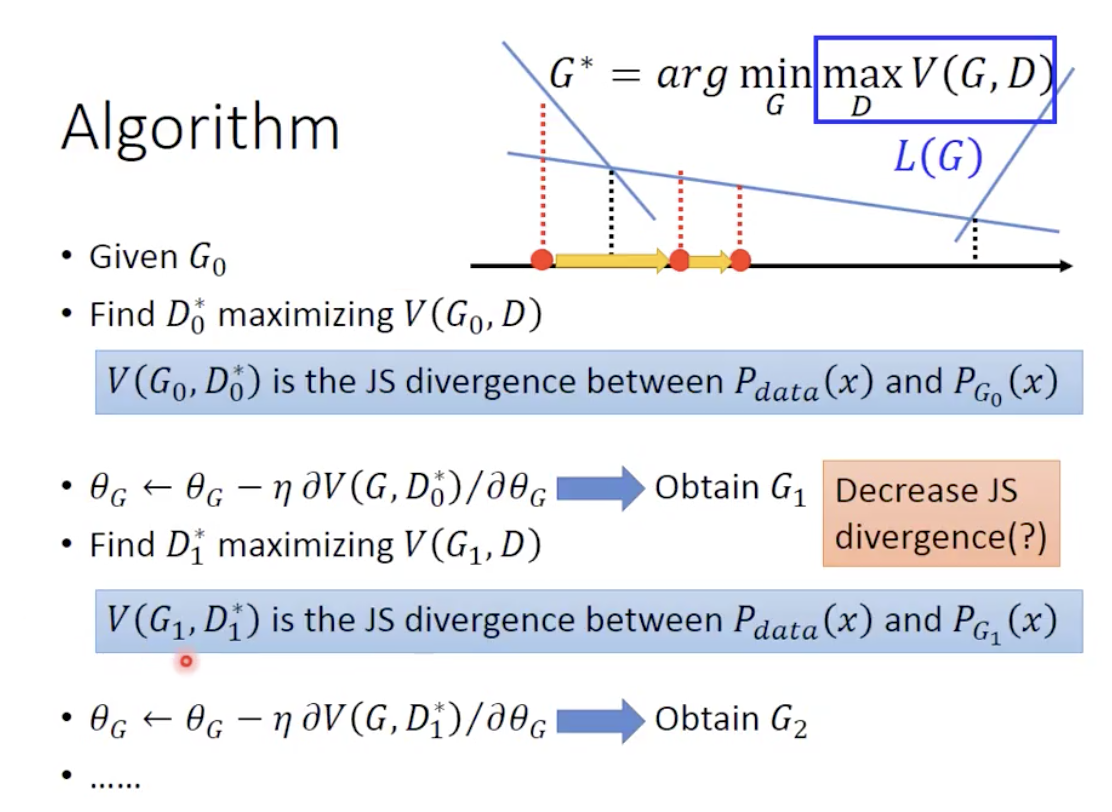
理论上的算法大致就如上图所示,不断地进行迭代即可。但是有一个问题,就是不能保证在下一次迭代中的 JSD 一定小于上一次,我们能做的也就是要求学习率比较小,尽可能避免出现 JSD 反而变大的情况。
但是在实现中呢,因为我们不能求期望值和积分,所以只能从真实样本中 sample 中 m 个样本,以 m 个样本作为全部的样本空间,再用一个 V_hat 代替 V:
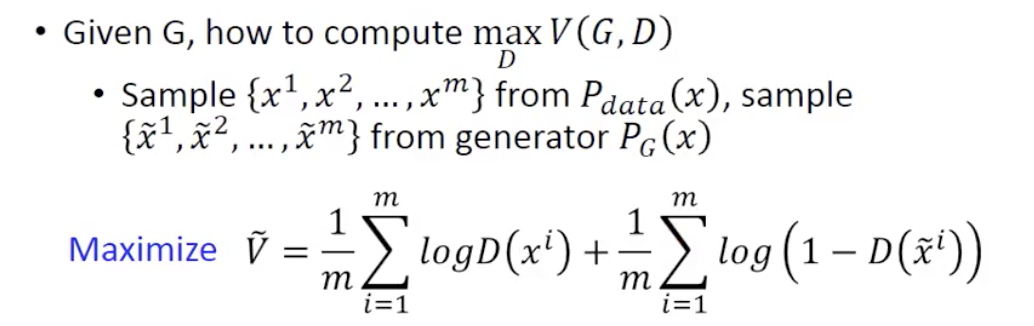
这个 V_hat 看起来非常的像 Cross Entropy 函数,要 Maxmize V,只要 Minimize -V 即可,我们把 -V 记作 L,对应我们一般模型中的 loss,那么就相当于我们要训练一个 Binary Classifier,来分辨数据是来自Pdata 还是 PG。

最后则是如上更为详细的实现过程,但仍然存在一个小问题,因为我们如果可以画出 log(1-D(x)) 的图像,我们会发现一开始的时候斜率很小,不利于学习,所以一般会将 log(1-D(x)) 改换为 -log(D(x)) 来更好的加快训练,但这样需要使得给 Generator 生成的数据打上 positive 的标签(这个细节有待日后验证)。
Problems
Discriminator Loss
如果我们去训练我们的 Discriminator,也就是一个 Classifier,会发现它的准确率高的可怕,几乎是 100 %,即 Discriminator Loss 基本为 0。其原因主要有两个:
- 实现上的原因:我们的采样不是全部的样本,导致两个分布实际上存在交集的分布“看上去”没有交集,而使得我们的 JSD 常常为 log2。如果我们要通过削弱 Classifier 来解决这个问题,就会导致参数非常难调整;而另一方面要想衡量 JSD,又要求 Discriminator 很强才行,这就存在了矛盾。
- 数据本身:PG 和 Pdata 本身是高维空间中的 mainfolds(流形),比如是两条曲线,其本身的交集很小,所以 JSD 通常接近 log 2,这就导致我们的算法没有足够的动力去进化。解决的方法就有 Add Noise,让 PG 和 Pdata 有更多的重叠的部分。比如在 Discriminator 的输入中增加 Noise,或者给输入的标签进行更换。这相当于增加了曲线的宽度,使得他们有更大部分的重叠,减小 JSD。当然这个 Noise 一般是会 decay over time。
Mode collapse
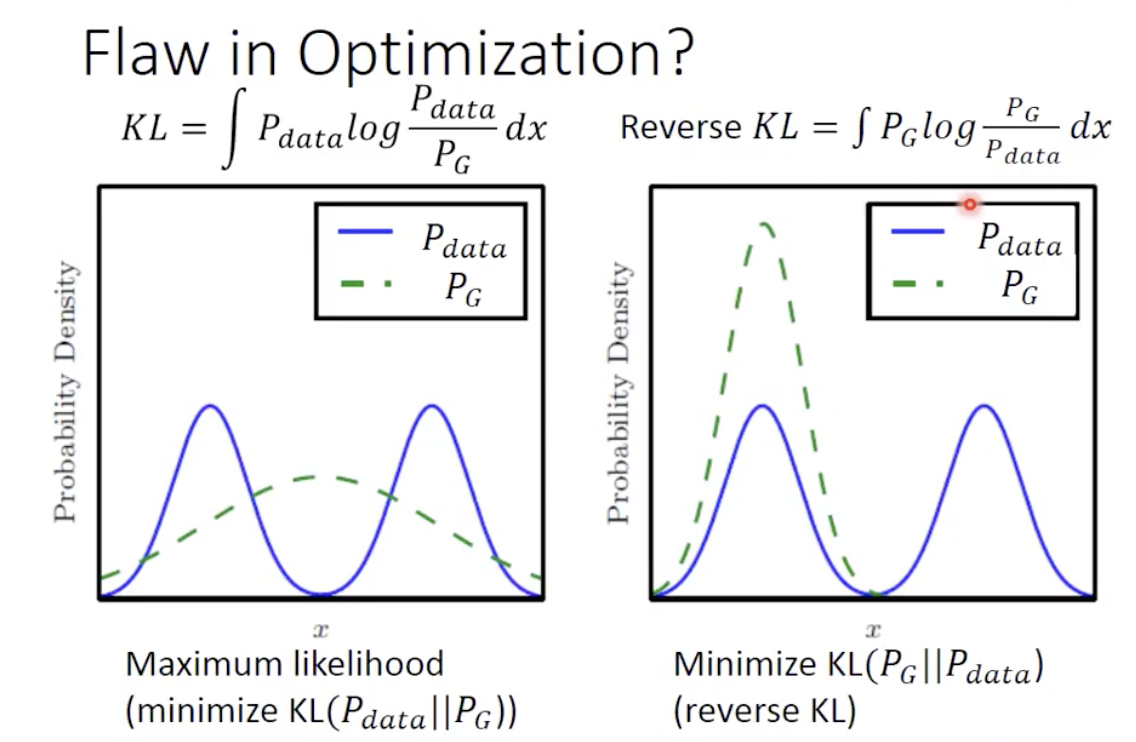
我们的模型会趋于保守,而无法 Cover 部分的 Distribution,在实际应用中比如图片生成,模型会趋向于生成大量重复的图片,而不愿意尝试生成的新的图片,因为这可能会带来巨大的误差。
Summary
基本照着李宏毅老师的视频记录下了这么多内容,算是对 GAN 有一个初步的了解。但 GAN 存在着很多问题,因而也存在着许多的变种来解决这些问题。还要学习一个啊!
PS:李宏毅老师台湾腔太萌了:哼,我有写错一个地方你们有发现吗,哈哈哈哈笑死我了。