
Attention Mechanism 学习笔记1
Attention Mechanism (注意力机制),是目前在 Neural Network 中应用很广的一种优化模型的方法,下一阶段的目标就是能够利用 TensorFlow 写出 Attention-based LSTM 来做 Text Classification 问题,这篇文章的目的就是记录学习过程中阅读 Paper、Blog 的理解和总结。
Attention
首先一个问题就是,什么是 Attention?我的理解就是一种 focus,聚焦在某一个局部。打个比方,当我们看到一照片,我们会不自觉地被某一部分所吸引,然后从这一部分向四周延伸出去,注意到画面的其他部分。当然这个吸引的部分可能因人而异,后续的向四周拓展的顺序也不一定一样。

拿上面这张图片来说,我先看到的是木房子的整体,然后关注到房子的条纹结构,再到远处的海边、山,最后是天空。这就是视觉上的注意力机制,在某种程度上说,这也是我们人脑为了节省计算资源的一种方式。
那么到了深度学习领域,我们会用 CNN 去处理图片,比如给图片起标题(Image Captioning)或者说是用 RNN 处理文本,做机器翻译(Neural Machine Translation,简称 NMT),如果同样地引入注意力机制,让模型更关注图片或者是文本的某一部分,是不是也能够节省计算资源呢?答案是,Yes!
从 NMT 说起
Attention Mechanism 第一次应用在 NLP 是 Bahdanau [1] 的这篇论文里,他是在之前的 Seq2Seq 的 NMT 模型上加上了注意力机制。
Our method uses a multilayered Long Short-Term Memory (LSTM) to map the input sequence to a vector of a fixed dimensionality, and then another deep LSTM to decode the target sequence from the vector.
Seq2Seq 主要就是 encode-decode 模型,先用一个 LSTM 把输入(一种语言)映射成一个固定长度的向量,然后再用另一个 LSTM 解码这个向量,从而得到输出(对应的另外一种语言),这样就实现了机器翻译,并且是不需要人工的标注等一系列费时费力的操作。而这个模型的缺点就在于:无论多长的句子,都会被编码成一个固定长度的向量,作为解码器的输入。那么对于长句子而言,编码过程中势必就会有信息的损失。
于是,Bahdanau 等人就提出了下图这样的模型:
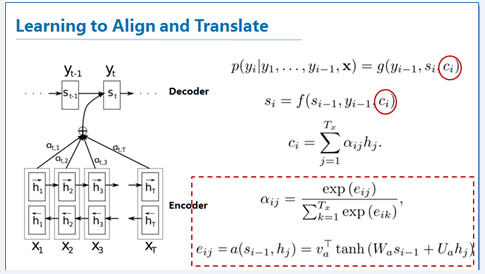
首先这有一个 Bidirection RNN,双向 RNN 作为编码器,这样做的好处就是能够在一些语序影响翻译(比如:句末词语对冠词、代词翻译提供参考)的语言中表现得更好。
在哪里体现了 Attention 呢?答案是: Ci,这个 Context Vector,上下文向量。
区别于 Seq2Seq 直接把最后一个时序 i 的输出 hi 作为上下文向量,而是将之前所有时序的输出通过加权求和得到的一个上下文向量。这个 Ci 包含着各个时序输出的权重信息,也就相当于告诉我们哪一段文字对于当前的 target word 是重要的,哪些是不重要的。这就相当于告诉我们的注意力应该放在哪里。
- Ci 是 Attention 矩阵的一行,表示输入 X1 到 XT 分别对 decoder 第 i 时序这个 target word 所对应的的权重(注意力大小)。
- αij 是 Attention 矩阵的一个值,表示输入表示 Xj 对 decoder 第 i 时序的 target word 的权重。
Attention 同时也可以看成是一种对齐模型,用来衡量输入端 j 位置和输出端 i 位置的匹配程度。
Attention 矩阵的计算方法如红框所示,由一个线性层和 softmax 层叠加得到。其输入是上一时刻 decoder 的状态 si-1 和 encoder 对第 j 个词的输出 hj,Wa、Ua 和 va则是需要我们模型去学习的参数。其对应的物理意义就是:句子中某个词对应正准备翻译的词的权重(重要性),由词语本身(hj)和前一个翻译的词( si-1)决定。不过这个函数(也叫Score函数)可以有别的形式,后面还会提到。
Soft Attention & Hard Attention
这种形式的 Attention 被称为 Soft Attention,软对齐(注意),因为每个输入词的 hj 都参与了权重的计算,这种方法方便梯度的反向传播,便于我们训练模型。对应的有 Hard Attention,就是在输出中找到某个特定的单词,其对应权重为 100%,其余都是 0。这种模型非常的粗暴,同时也因为在文本中一一对应的难度太大,而且这样我们模型的训练会变得非常困难,需要很多优化的技巧,所以很少会 NLP 中使用 Hard Attention;但是在图像处理领域,Hard Attention 被证明是有用的。
Global Attention & Local Attention
Our various attention-based models are classifed into two broad categories, global and local. These classes differ in terms of whether the “attention” is placed on all source positions or on only a few source positions.
这是 Luong [2] 论文中对于两种 Attention Model 的描述,其核心的区别在于:
上下文向量的 C 的计算中,是否所有 Encoder 的 hidden states(hi) 都参与了计算:
全部参与计算就是 Global Attention,只有部分参与,则就是 Local Attention。
Global Attention
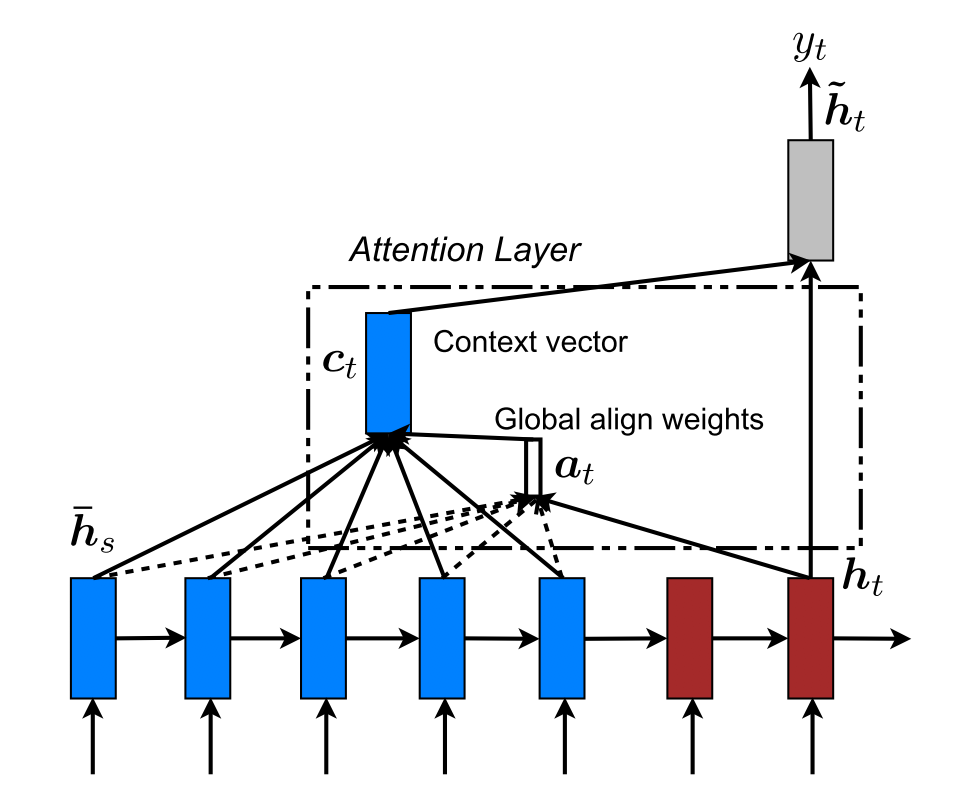
如上图所示,蓝色部分是 Encoder,所有的 hidden states 都参与了 Ct 的计算。
权重 at 和 Bahdanau 一样,通过一个 Softmax 函数来计算,只不过这里的 Score 函数有所不同:
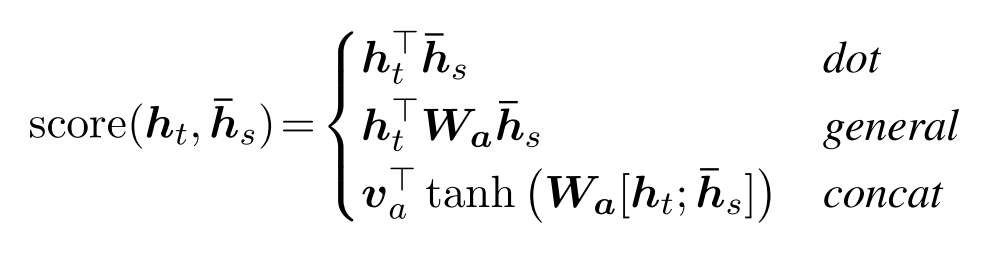
Bahdanau论文中用的是第三种,而在这篇论文中发现,第一种对于 Global Attention 效果更好,而第二种应用在 Local Attention 效果更好。
Local Attention
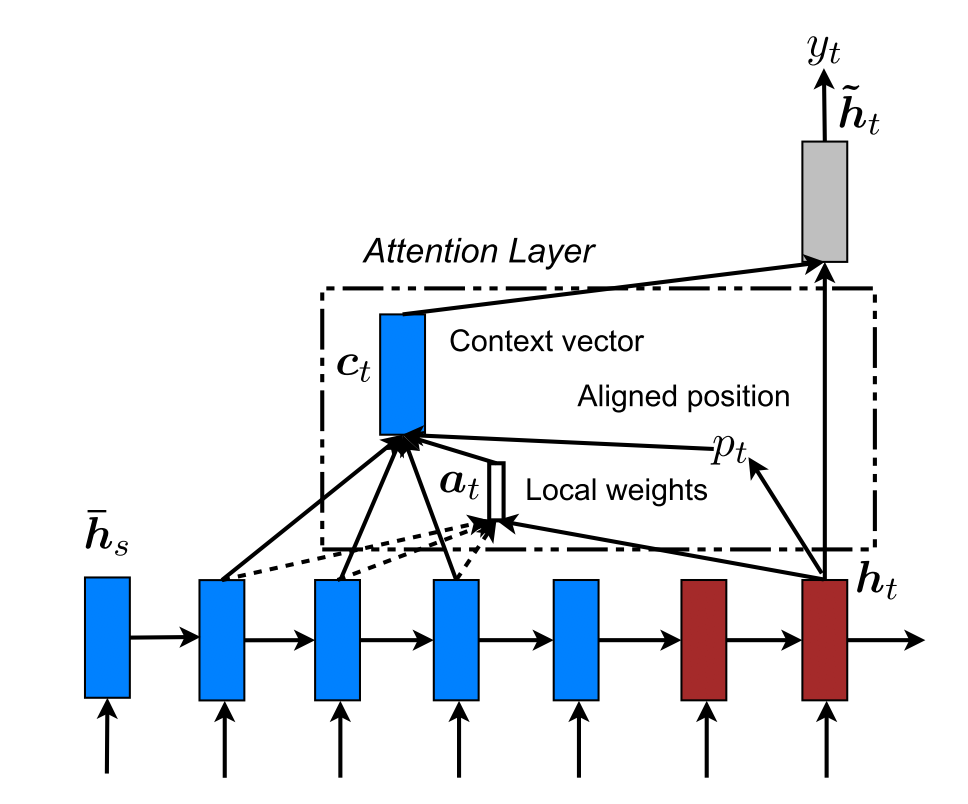
如上图所示,这里很明显的不同是:只有部分 hidden states 参与了 Ct 的计算,另外多了一个 pt,这是用于指示对齐位置(也就是哪一部分 hi 参与上下文运算的计算)的一个实数。
Local Attention 模型的流程是:
- 计算位置对齐参数 pt
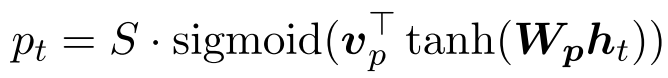
这里的 S 是源句的长度,这样通过 sigmoid 函数我们就能保证 pt 一定在我们的句子范围之中,v 和 W 都是需要模型去学习的参数。另外一种对齐参数是直接粗暴的一对一,认为 p<sub>t</sub> = t,这个在 NMT 场景中明显是不符合逻辑的。
- 选取在窗口范围[pt - D,pt + D]的 hidden states,计算权重向量 at
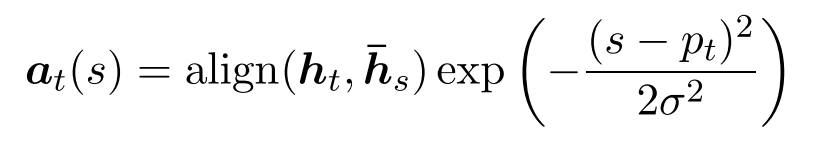
这里的 D 是通过经验选取的参数(玄学),而 at 就是一个固定长度为 2D+1 的向量,实际上就是在原来的对齐函数乘上了一个高斯分布来体现距离对权重的影响。