
Attention-based LSTM for Text Classification
经过了前面一段的铺垫学习,总算走到了这次的目标:利用 TensorFlow 实现 Attention-based LSTM 来做 Text Classification,主要是在前面一篇文章讲的 TensorFlow 提供的 RNN(GRU) Model 上面添加 Attention Mechanism,注意力模型的实现上,我主要参考了 Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification 这篇论文。
原理
上面那篇文章和我想做的东西是非常类似的,唯二的两个区别是:
一、它使用了一个双向 LSTM 来解决长句子后半部信息丢失的问题,我只是用了单向的 LSTM
二、它做的是 Relation Classification,而我是 Text Classification。
Attention
论文中 Attention 的公式如下:
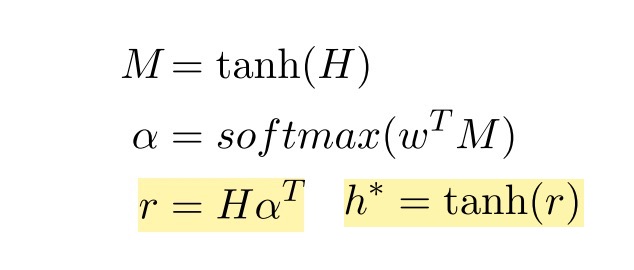
T:文档的长度,在我们的代码里被设置为 MAX_DOCUMENT_SIZE
H:每个 LSTM 的 output 的集合,即 [h1, h2, … , hT],维度:(Embedding Size,T)
α:注意力向量,也就是一个 h 的权重分布向量,我们通过 W^T^H,希望能够模型学习得到 Weight,进一步得到 α,维度:(1,T)
r:加权后的 H,维度:(Embedding Size,1)
h*:最后的输出,添加一层 tanh ,把值变换到[-1, 1]区间,维度:(Embedding Size,T)
Classifying
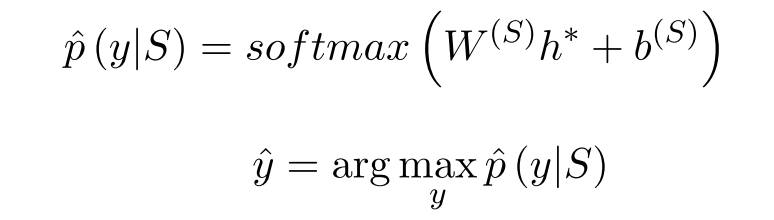
通过 Softmax 函数我们得到一个类别的概率向量,然后再用 argmax 函数的结果作为我们最终的分类。
Explanation
其实我们可以通过几个向量的维度窥得其中几个重要的物理意义:
- α 的维度和文本长度相等,注意力向量的加权的思想体现在这里。
- r 向量的长度和词嵌入的长度相同,可以认为是把整篇文章通过 Attention Model 变成了一个 Topic Word,随后我们通过学习 Softmax 层的 Weight 和 Bias 来找到各个 Topic Word 在词嵌入的高维空间之中对应的类别。如果能够把结果 plot 出来,应该能看到同一类别文本的 Topic Word 是相近的。
TensorFlow 实现
|
|
Result
限于篇幅这里就不贴出数据准备和训练的代码,完整代码在我的 GitHub 上。
在 lr=1 , batch_size=128, train_steps=1000000 , Embedding Size =50 ,Max Doucment Size = 20,以及没有 dropout 和 regularization 的情况下,模型最后在测试集上的准确率在 80% 左右,结果差强人意,应该还有需要大量改进的地方,有待日后补充。
Update
9.3: Change Embedding Size to 100: Accuracy 91.7%
9.4: Change Max Document Size to 25: Accuracy 93.4%
9.22:重写了代码,把 Word Embedding 的训练和 Attention-based Bidirectional LSTM 训练放在一起,5 个 epoch 之后,Accuracy: 98.3%