
别人家的 Attention
Attention Is All You Need 前段时间火了一把,其提出完全用 Attention 替代传统的 CNN 和 RNN 架构来做特征的提取,也在 NMT 上也取得了 state-of-the-art。这两天读了一下这篇 Paper,并且在熟悉的 Text Classification 问题上用其模型做了一下尝试,这篇 Blog 就用来记录过程中的一些想法和感受。
What is Attention
注意力机制之前在学的时候就有过一次梳理,上一次对于什么是注意力机制,我的回答是:
聚焦在某个局部的 focus
现在我的回答是:Attention(一般指的是 Self-Attention),是特征提取过程中,信息融合的手段。其目的是能够让模型的信息视野有的放矢,其数学上的表现就是加权和。
NLP community 曾经有过这么一种说法:
an LSTM with attention will yield state-of-the-art performance on any task
以及这样一张图:
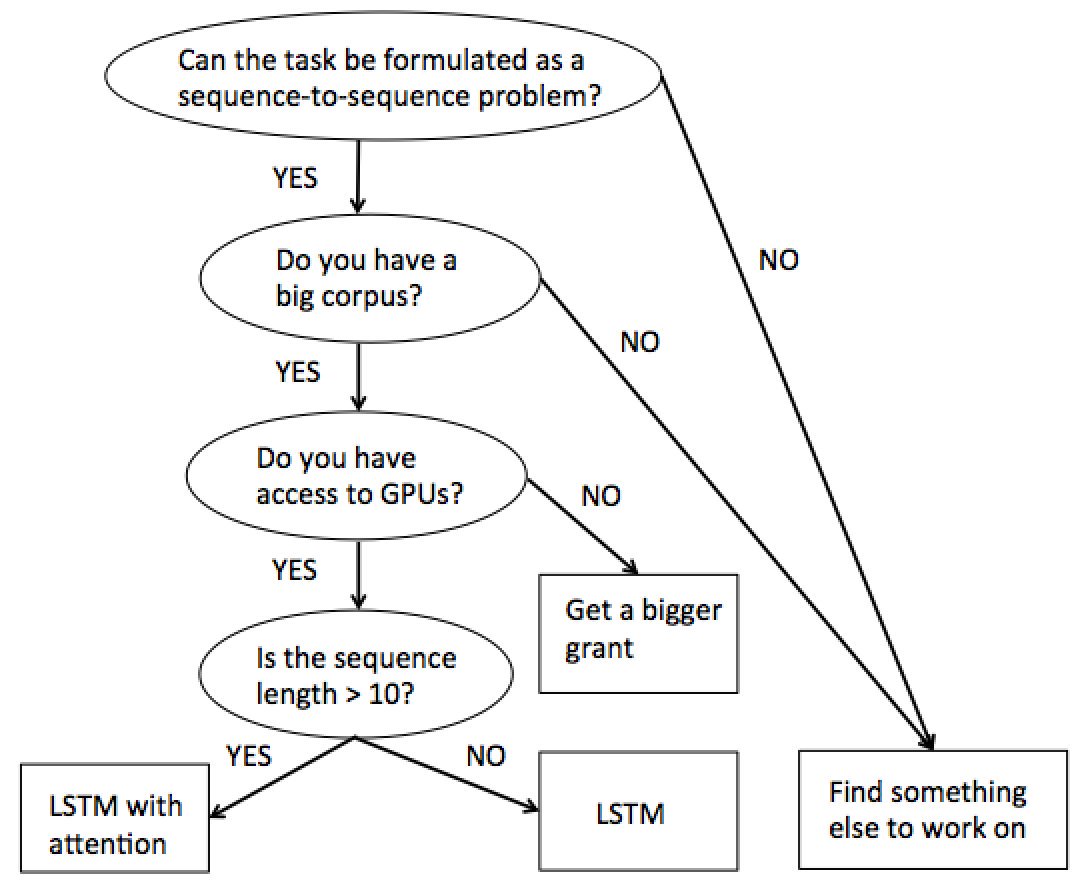
中心思想就是:Attention + LSTM 是一个非常 Powerful 的 model,基本能在所有的 NLP 任务上 work。就我有限的经验来说,大抵如此了。特别是 Attention,简直是即插即用效果还特别好的万金油。
而论文中对 Attention 的定义是这样的:
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors.
这里的 query、key、value 是理解的重点:
对于机器翻译任务来说,在传统的 Seq2Seq 架构中,假设我们将要输出第 k 个词,那么这个 query 就代表这第 k 个词对应的 hidden state,key 和 value 一般是相等的(作者也提出了一种不相等的方式,详见下图),即之前 encode 的所有 hidden state:
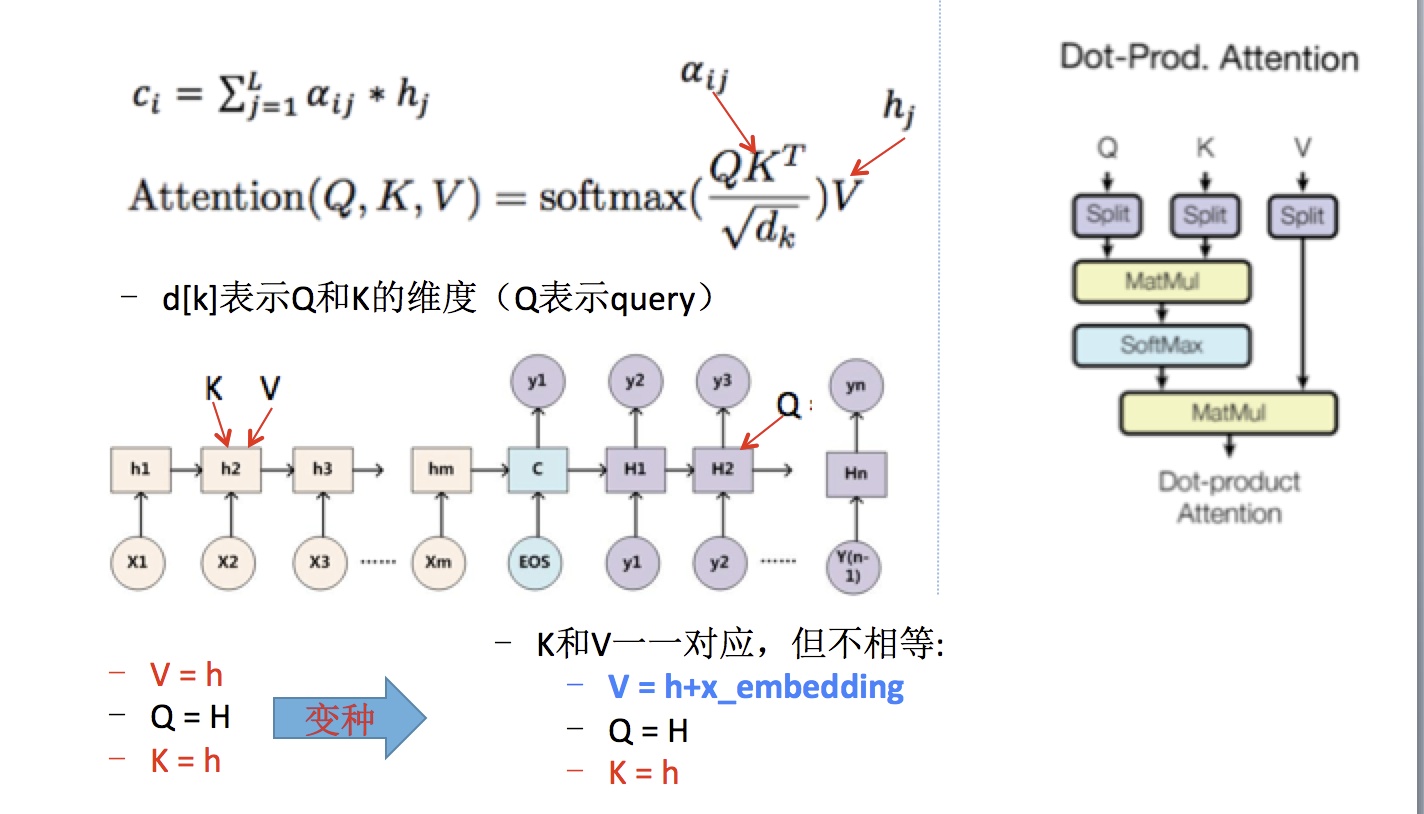
一开始提出 Attention 的使用一个 Alignment Function 来描述,并且提出了几种 score 的计算方式。这里的计算公式就是用最普通的矩阵乘法:
$Attention(Q, K, V) = softmax( \frac{QK^T}{\sqrt{d_k}})V$
Softmax 项就是权重项,$V$ 是一系列 hidden states,也就是说,attention 最终的表现形式依旧是加权和。
Multihead Attention
到了本文最重要的部分, Multi-head Attention。作者的 Motivation 认为是原有的 RNN 和 CNN 并行化不够,太慢了;同时觉得原先的复杂度太高,像 RNN,从头滚到尾关于序列长度是一个 $O(n)$ 的复杂度。所以期望单用一个 Attention 来做特征的提取,因而提出了 Multi-head Attention。
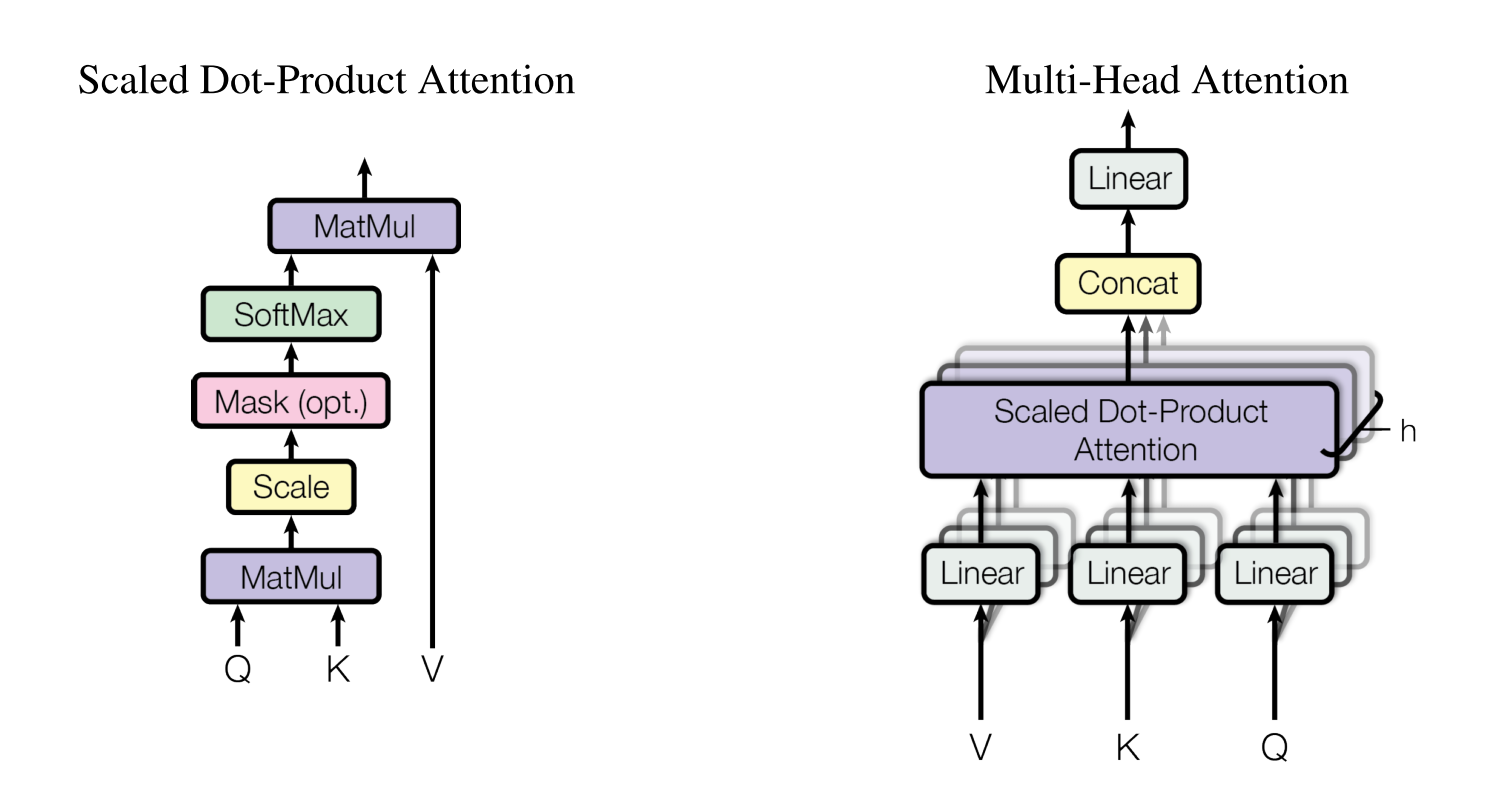
$MultiHead(Q, K, V) = Concat( head_1, … , head_h) W^O$
$head_i = Attention(QW_i^Q, KW_i^L, VW_i^V)$
就是先让 Q,K,V 做一个线性的投影(分别乘上个矩阵),再做 Attention,这样重复多次,将结果拼接起来,得到一个“多头” Attention。
背后的动机是什么呢?文章中这样说:
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions.
一方面,从直觉上多次 Attention 操作就能够捕获更多的信息;另一方面,先进行的投影操作能够把 Q、K、V 映射到不同空间,也许能够发现更多的特征。
然后再给他套上一层全连接:
$FFN(x) = ReLU(xW_1 + b_1) W_2 + b_2$
这样的 Attention 操作没有考虑到时序信息,但序列位置的信息还是很重要的,因此,作者对位置信息进行了 Encoding:
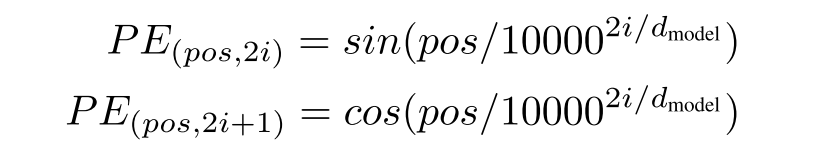
同时文章还仿照 CNN,增加了常用的 Residual Connection 以及 Layer Normalization 操作,这里就不再展开。
Implementation
该 Paper 有 TensorFlow 的开源实现,侧重看一下 Multi-head Attention 以及 FFN 的实现:
|
|
基本就是按着 Paper 来的,不过一个很让人费解的地方就是其中的 Key Masking 和 Query Masking,Paper 中写是 Optional 的,代码的作者非常细致的实现了这一部分。其目的是考虑到变长的序列,比如第一句的长度为 128 而第二句只有 64,对于第二句,其 Encoding 的结果或者说是 Hidden State 的后面 64 个单元是没有意义的,因此将其设置为一个非常小的数,从而对应的权重接近 0;Query 类似。具体内容可以参考这个Issue。
|
|
FFN 的实现就很简单,用两个 conv1d 的卷积,手动写矩阵乘法也可以;另外就是最后两步的 Residual Connection 直接加上输入以及 Layer Normalization。
PS:我拿着这个代码跑了一下 IMDB 的文本分类,只用了 Multi-head 和 FFN,Query 是一个随机初始化的向量,Key 和 Value就是经过 embedding 后的句子。 和 LSTM 对比下来,时间是 LSTM 的 6 倍,效果比 LSTM 还差… 为什么呢?因为没有并行化,事实上那些矩阵乘法都是可以用多块 GPU 来并行进行的,论文就说他们用了 8 块 P100。流下了没有钱的泪水。