
BPTT 推导
写 IndRNN 解读的时候,对于 RNN 求导那一块其实没什么底气,因为框架都帮你实现了,所以学的时候也都避重就轻地略过去了。但 Back Propagation Through Time (BPTT) 是绕不过去的,这就是地基,不把基础打扎实了,就会发生“眼看他起高楼,眼看他楼塌了”这样的悲剧。
矩阵求导
首先是矩阵求导,可以参考一下矩阵求导术,这里就给出两个最用的公式:
- $ \mathbf{J}_{i,j} = \frac{\partial f_i}{\partial x_j\ }$,其中: $ \mathbf{f} : \mathbb{R}^n - > \mathbb{R}^m$ 是一个 n 维到 m 维的映射,其求导的结果是一个雅各比矩阵,其中元素为 $f_i$ 对 $x_j$ 的导数
- $ \mathbf{f} = A\mathbf{x}$, $ \frac{\partial f}{\partial x} = A^T$
在这两个式子的基础之上,就可以开始我们的求导啦~
BPTT
来一起默写一下 RNN 的公式,其中 $\sigma$ 代表激活函数;:
\[\mathbf{a}^{(t)} = \mathbf{b} + \mathbf{W} \mathbf{h}^{(t-1)} + \mathbf{U} \mathbf{x}^{(t)}\] \[\mathbf{h}^{t} = \sigma (\mathbf{a}^{(t)})\] \[\mathbf{o}^{(t)} = \mathbf{c} + \mathbf{V} \mathbf{h}^{(t)}\] \[\hat{y}^{(t)} = softmax(\mathbf{o}^{(t)})\]这里我们用双曲正切 $tanh(x)$ 作为激活函数,其导数为 $ 1 - tanh^2(x)$ ,并且假设最后输出层使用 softmax 函数来得到一个概率向量。
来进行愉快地求导吧,记住一点原则,由外向内一层层求导。
如果我们的 Loss Function 是一个负对数似然,则对于 t 时刻对 $o^{(t)}$ 导数的第 i 个单元的值为

因此,我们就可以很轻松求出 Loss 对最后一个时刻 T 的 $h_T$ 的导数。
有了最后一个时刻 T 的导数之后,我们通过反向迭代,从 $t = T -1$ 一直到 $ t = 1$,对 $h^{(t)}$ 求导:
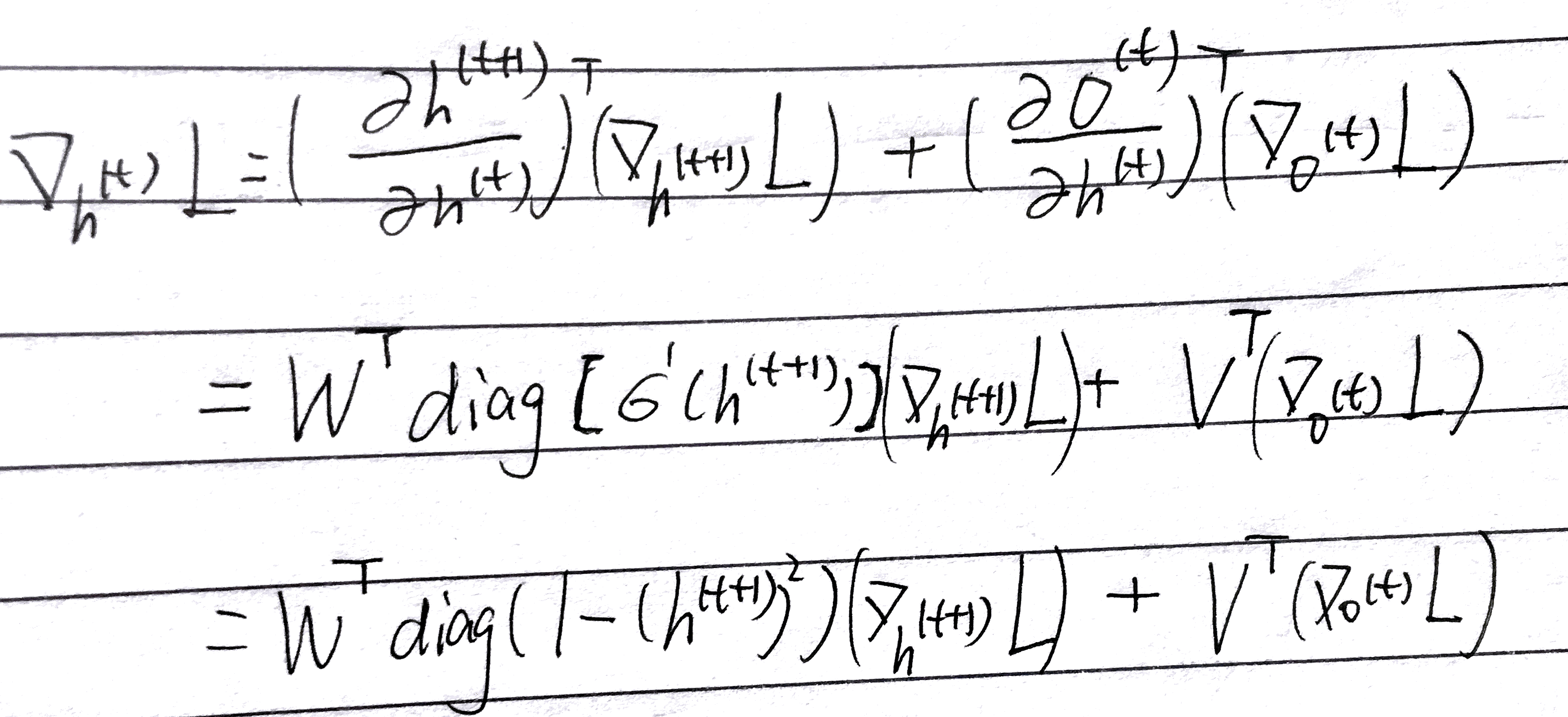
注意,这里的导数由两部分组成,一部分直接来自 $o^{(t)}$;另一部分,因为 $h^{(t+1)}$ 的计算依赖于 $h^{(t)}$ ,所以这一部分的梯度也从下一时刻流入。梯度不仅来自于当前输出,还来自于下一时刻的输出,这也就是 BPTT 名字的由来。这里的 diag 是对角阵,其产生的原因是因为我们的激活函数 $tanh(x)$ 是一个 element-wise 的操作,形状不变,求导得到的雅各比矩阵是一个方阵;同时,又有 $\mathbf{J}_{i,j} = 0, i != j$(还是因为 element-wise,结果只和原来对应位置上的元素有关),因而只有主对角线上的元素不为 0,而是 $tanh(x)$ 的导数,因此结果就如上图所示。
有了以上的结果,我们再对我们需要更新的偏置和权重变量进行求导就方便了很多,首先是偏置:
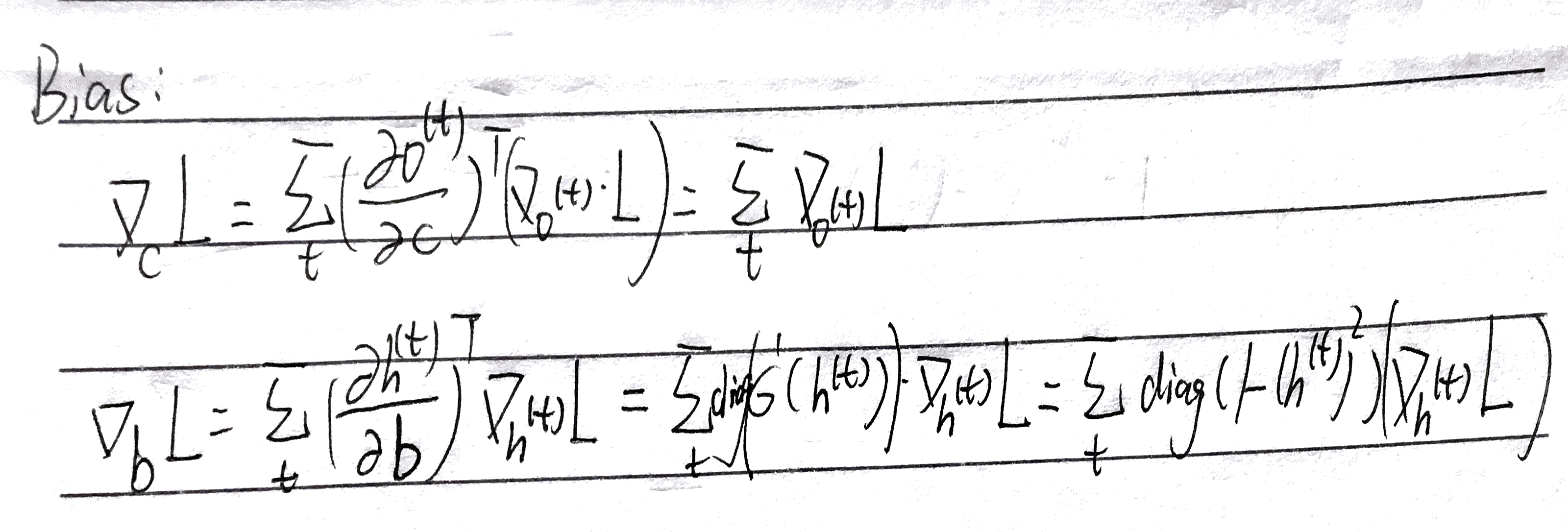
同样需要注意的是这里也有一个 diag,同样是因为激活函数存在的缘故,不再赘述。
权重矩阵也类似:
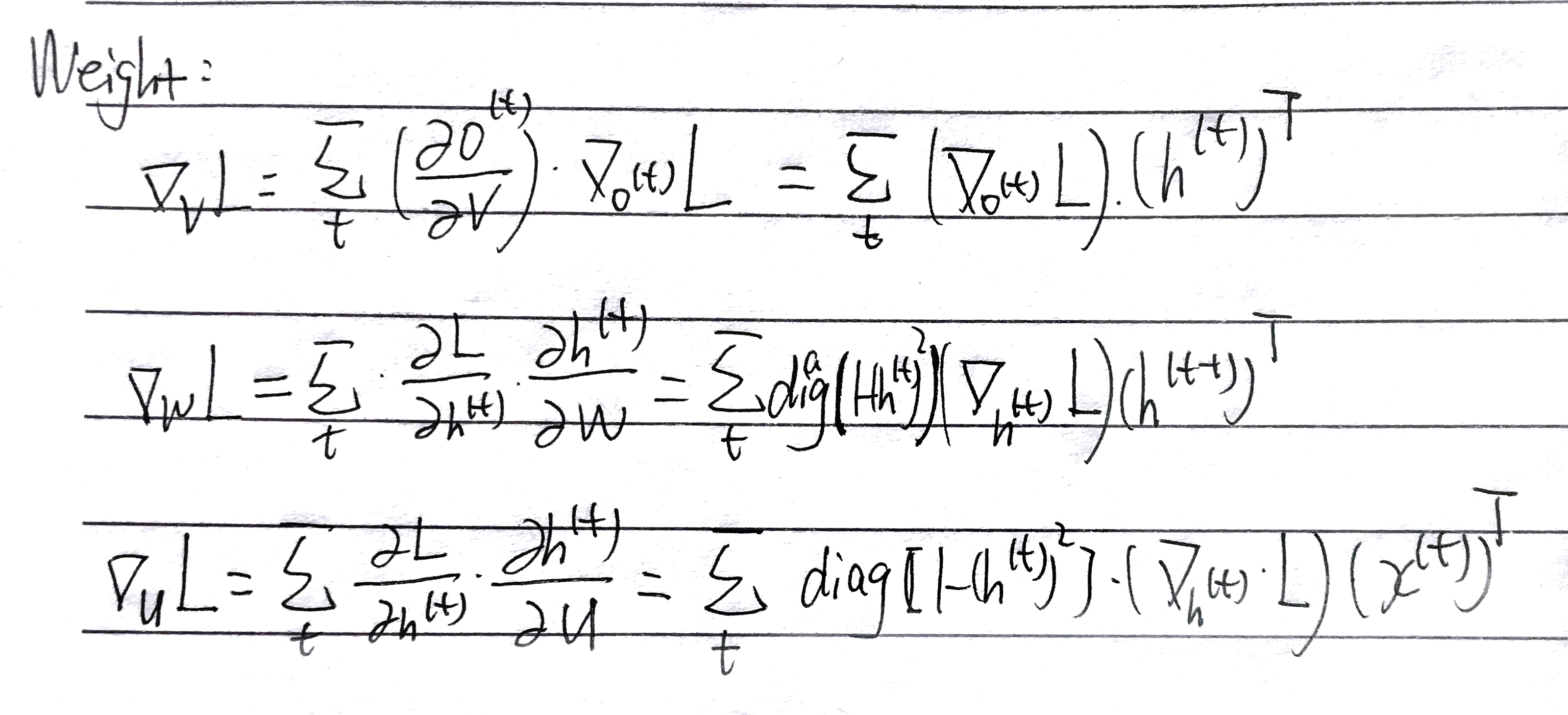
至此,所有需要更新的变量的求导就已经完成了,这里诸如转置和矩阵乘的位置的细节不必太过纠结,知道整体的思路就可以我认为。
再来看梯度消失问题
求完导之后我第一反应就是找矩阵乘法,发现就根本没有乘法啊,只有一系列求和?其实是隐藏在在 $ \nabla _{h_{t}} L$里了;如果我们简化一下这前向传播的过程:
\[\mathbf{h}^{(t)} = \mathbf{W}^T \mathbf{h}^{(t-1)}\]进一步递推得到:
\[\mathbf{h}^{(t)} = \mathbf{(W^t)}^T \mathbf{h}^{(0)}\]然后我们再用特征值分解的方法,来计算这个连乘:
\[\mathbf{h}^{(t)} = \mathbf{Q}^TA^t\mathbf{Q} \mathbf{h}^{(0)}\]特征值不到 1 的,在 t 次之后,就衰减为 0;超过 1 的,则会激增。那么 $h^{(0)}$ 中不与最大特征向量对齐的部分就会被丢弃。
这是从正向传播的过程来看梯度消失,其表现就是后面的状态把前面的忘干净了,也就是长期依赖的问题。
不过简化分析的时候我们没有考虑激活函数,采用的激活函数的导数也是有界的,比如 tanh 导数就小于 1,sigmoid 导数小于等于 0.25,这个导数也是参与到连乘中的结果也会导致梯度急速下降,这也可能就是梯度消失概率比爆炸概率大得多的原因之一。
Reference
推导的过程主要参考了花书《Deep Learning》中文版,此时突然想到高中老师的一句话:人生需要几本垫底的书。希望花书能成为替我垫底的几本书之一吧。