
LLM101-Parallelism学习笔记
ChatGPT 大模型的时代到来了,怎么样才能不做一个 Prompt 工程师呢?那自然是学习如何训练大模型了。个人理解,大模型的训练的目标函数并不难,就是 language modeling 的极大似然估计,难的是大规模算力的调度和高质量数据的清洗。而这方面的经验和技术储备,很多的同学因为受到实验室的资源限制,其实是远远不够的,那我们能做的,就是通过尽可能地和公司合作,并且熟练地掌握分布式的训练框架,这些框架的核心就是各式各样的并行,这篇 Blog 就来分享一下学习并行机制以及 megatron LM 的相关代码。
几种并行机制
Data Parallelism
数据并行是之前做单机多卡(Single-node multi GPUs)最常用的一种方案,其核心就是在不同 GPU 上分别 host 一个模型,从而每块 GPU 能够拥有自己的一部分 dataset subset,达到一个亚线性的加速,例如,使用八块 GPU 训练会比单块 GPU 快大约八倍不到的速度。之所以无法达到完全的 GPU 数量倍数的加速比,是因为各个 GPU 所 host 参数需要在梯度更新后进行参数同步,即:
- 各个 GPU 单独在自己的数据上计算梯度
- 对各个 GPU 的梯度进行平均,将平均后的梯度分发给各个 GPU
- 各个 GPU 利用得到的平均梯度对参数进行更新
- 利用某些 Barrier 机制来确保各个 GPU 的参数都完成更新后,进行下一个 batch
第二步中需要在 GPU 之间进行大量的数据传输,造成对训练吞吐量的影响,当然有一些异步的机制来降低这一数据传输的开销,但一般这种开销也基本可以接受,使用原版的数据并行就可以了。
Pipeline Parallelism
如果模型的参数特别大无法 fit 到GPU 的显存中,数据平行就无能为力了。Pipeline Parallell 的解决思路就是将模型的不同部分放到不同 GPU 上,直观的理解就是把多块 GPU 的显存都拼接起来,合成一块更大的显存的 GPU。对于 Transformer 模型,最直接的 pipeline parallel 就是根据 TransformerLayer 来切块(例如,总共 32层,8块 GPU,则我们可以在每块 GPU 上放 4 层),然后将不同的块放到不同的 GPU 上。由于层和层之间的依赖关系,例如,8-4层的计算依赖于 0到3层的结果,则对应 GPU 上的计算需要等待前序块的 GPU 完成计算,这种等待被称之为气泡 bubble,同样会降低计算的吞吐量(学过操统的流水线的同学应该会感觉非常熟悉)。
如何降低气泡数量从而提升计算吞吐量呢?我们可以尝试将计算的粒度变小,即复用 Data Parallel 的思路,在等待的时候,计算下一个小 batch,从而用小 batch 的计算来填补等待的空白,对应地,梯度计算的时候也复用数据并行的方案即可,然后进行 GPU 之间的传递。因为前向计算和反向梯度传播之中都包含结果或者是activation 的传递,以及有多卡多 minibatch 之间的聚合,这里存在巨大的调度设计的空间以提升效率。GPipe 和 PipeDream 则是两个代表性的方案,前者分别地处理前向和反向的计算(完成所有 batch 的前向后再进行反向传播),而后者则是当第一个 minibatch 的前向完成之后即可进行反向的计算,因而更能够降低等待时间。


Tensor Parallelism
张量并行则是更细粒度的计算层面的并行机制。相较于 Pipeline 在层和层之间切分,张量并行则是在层内部,对基础的矩阵操作进行切块。 Transformer 模型的主要计算单元 FFN 和 Self-Attention 中存在大量的矩阵运算,而矩阵运算又可以被视为是列向量和行向量的点积,而行-行/列-列之间的计算是相互独立的(或许最后需要求和汇总),因此我们可以将矩阵切块放到不同 GPU 上,进一步提升并行度。MegatronLM 对此有比较直观的图解:
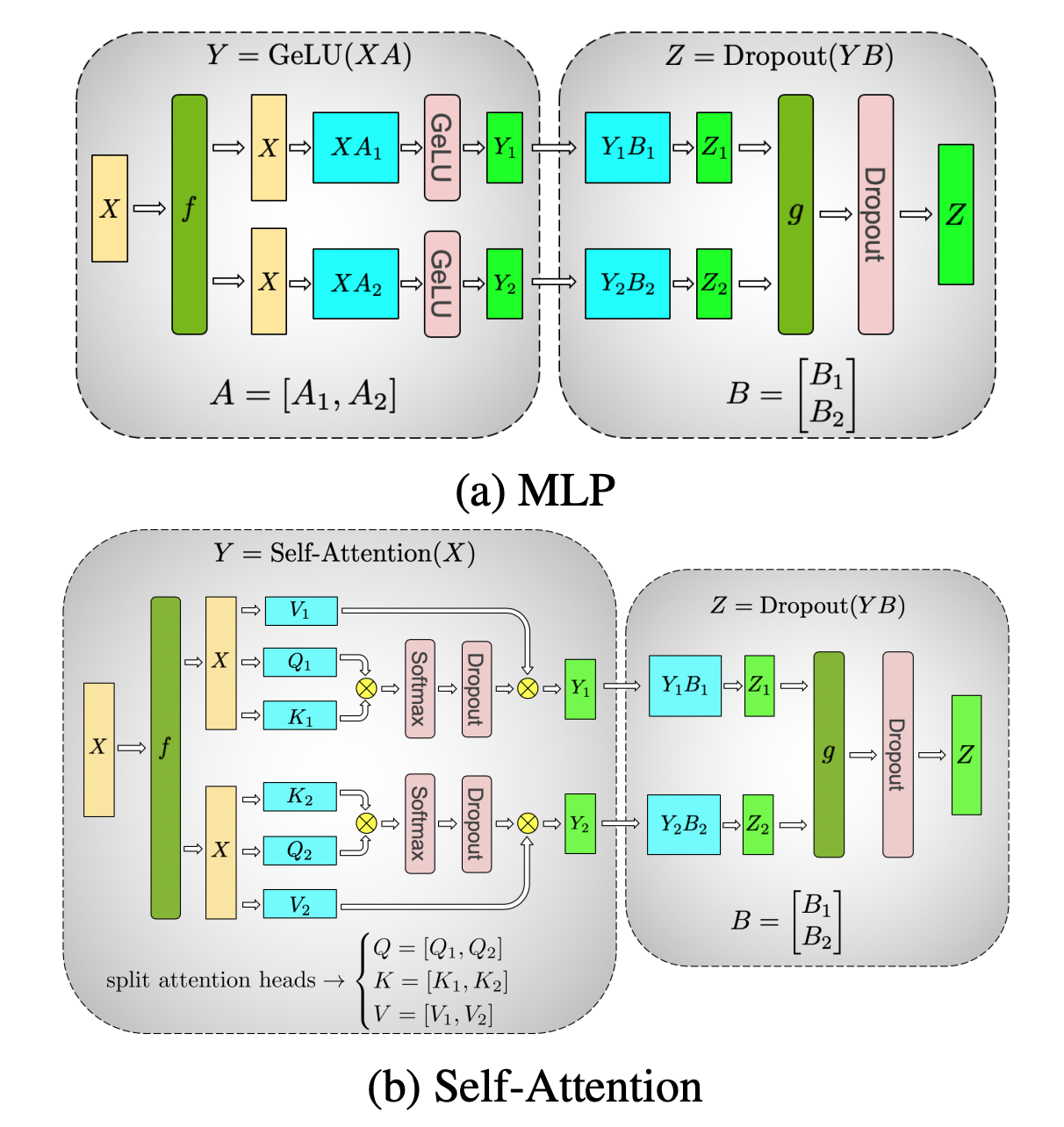
具体地,给定一个矩阵乘法操作:
\[Y = GeLU(XA)\]其中 $Y$ 和 $X$ 分别对应输出和输入,$A$ 则是一个权重矩阵,则我们有两种对 $XA$ 进行分割的操作:
第一种将输入按列分块$ X = [X_1, X_2] $,将权重按行分块$A = [A_1 ; A_2]$ (分号表示 A1, A2 的列数相同),
则我们需要对结果进行聚合得到
\[Y = GeLU(X\_1 A\_1 + X\_2 A\_2)\]而因为 $GeLU$ 是非线性函数,$GeLU(X_1A_1 + X_2 A_2) != GeLU(X_1A_1) + GeLU(X_2A_2)$ ,因而在得到最终的结果之前还需要进行一次聚合;
另外一种切割则是将 $A$ 按列切分,则有 $A = [A_1, A_2]$,对应的可以得到 $[Y_1, Y2] = [GeLU(X A_1), GeLU(X A_2)]$,可以单独计算每个部分而不需要一个同步节点用来求和,因而可以降低 GPU 之间同步所需要的通讯量,但在 dropout 之前需要对所有结果进行一个聚合操作(类似 GeLU 的非线性),第二种切分方式对应的示意图如下:
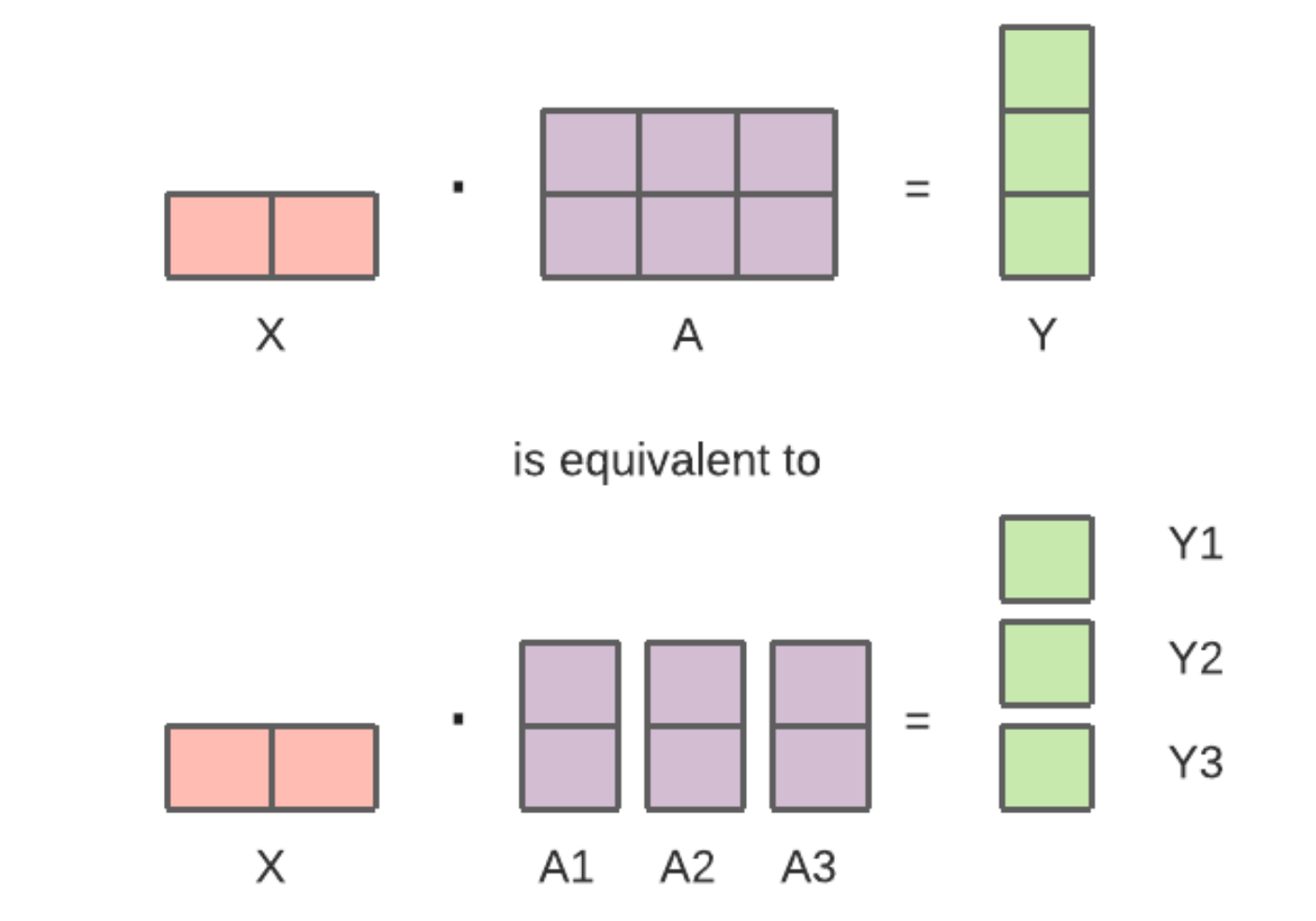
对应到具体的实现,则可以在 MegatronLM 里找到两种分割的实现,分别称之为 ColumnParallelLinear 和 RowParallelLinear。
其核心就在于 weight 权重的初始化分别是:
|
|
以及 RowParallel(即第一种实现)需要在前向中进行 AllReduce。此外,因为 ColumnParallel 得到的输出 Y 天然是按列分块的,因而可以在后面接上一个 RowParallel(输入是按列分块,权重按行分块),而只需要做一次 reduce 操作即可完成 MLP 的计算。
Parallel Vocab Embedding
语言模型里的 Embedding matrix (look-up table)其实也可以看做是一个大规模的矩阵乘法运算,因而也可以通过张量并行来实现:
|
|
因而当我们在 load 大规模语言模型特别是利用 tensor parallel 训练的模型的时候,需要确保模型的对应的设置也正确,否则则会出现 load error ,即参数形状不对(例如 50000 的词表可能被分成四块,每块 12500)的问题。
对应的,Output Embedding (输出为词表概率的矩阵)也可能做了对应的并行,并且和 CrossEntropy Loss 一起考虑进行相应的 mask 后的计算。
Takeaway
以上提到的几种并行策略都可以叠加使用,达到更好的并行效果。此外,我们也会注意到,更细粒度的并行意味着和模型结构更高的耦合,即需要对模型的结构、计算有着特定的假设才可以使用对应的并行策略,而不存在某种策略适合所有的模型。最后,附上 Huggingface 给出的并行选择的方法:
-
单卡:模型放得下就可以不用并行;显存放不下可以考虑使用 ZeRO 和 Offload CPU(将 optimizer state 放到 CPU 上)
-
单机多卡:模型放得下可以使用数据并行和 Zero;放不下则可以考虑 Pipeline Parallel(PP),ZeRO 以及 Tensor Parallel(TP)。几种方法的在 GPU 通讯带宽较好的(e.g., NVLINK A100)的场景下速度,否则 PP 会更快,而 TP 的效率取决于如何配置,可以多尝试不同的并行度;
-
多机多卡:节点之间通讯比较好的话考虑 ZeRO 或者 PP + DP + TP;节点通讯带宽差并且单个 GPU memory 较少,则考虑:DP+PP+TP+ZeRO-1