
读博和 AIGC
朋友们,好久不见!或许大家都以为这个博主失踪了,很久没有正经的技术 Blog 和碎碎念更新了(也可能并没什么还在关注这个 Blog 哈哈)。博主并没有失踪,也不至于说忙到没时间吹水,表达的欲望总是存在的,只是很多时候会在和朋友们分享之后,敲键盘码字的动力就会少一些,Typora 收费也一度让我打不开我的 Markdown 编辑器。好在,最终支持了一波 Typora(看在它陪我写了这么多文章的份上),也再次写一篇新的文章和大家分享一些最近的所思所想。主要是两点:关于我决定读博的心路历程 & 对 ChatGPT 和 AIGC(AI generated content) 内容的感受。
A Decision for a PhD Degree
时间拨回到大半年前,摆在我面前的有两个选择 (a) 继续读博(国内的话是本组 / 境外的话考虑到国际形势和时长可能优先欧洲和香港)(b) 校招找工作(大概率也是成为搜广推的一员)。在一年多前,我也已经在为找工作做准备(主要指刷题哈哈)。说到这个,我发现刷题本身还是挺有意思的,不过刚开始刷的那段时间( 题量 < 200)会比较痛苦,碰到难题抓耳挠腮好久也无果只能看题解;刷了 200 道左右之后慢慢会开始有感觉,简单题基本能做,难题㛑大致知道应该往哪个方向思考;500 道左右的时候,感觉基本能够应付大部分的面试。我始终认为面试做算法题并不是作为一个筛人的门槛,而是在一个短时间内,面试官了解你的一个过程,做对题目可能只占 50%,剩下 50% 在沟通(和面试官沟通理解题意正确无误,有想法的时候也可以和面试官确认一下思路是不是正确)和代码风格(这个是长期 coding 的习惯)等方面。秒题固然很好,做不出也不用太受影响。读博的话我的经历也算丰富,一路从 LSTM + Attention 到 BERT 到 GPT-3 like models,做过 A+B 也挖过一些小小的水坑(厚脸皮)算是一个熟练工了,应该也能够找到不错的去处,至于毕业之后的出路,或许大家会对教职之类的有很多焦虑,但我相信努力的孩子终归还是能够在工业界或者是学术界找到一份 decent 的工作的。我这边简单对比了一下两个选项在各个方面的优劣:
- 经济: 工作 (大概率)(远)大于 读博。这一点是很多读完硕士同学特别会注重到的一个地方,按平均 50w 的 package 来看,四年的博士的机会成本就是 200w 起步,特别是国内的博士,补助很低,刨去生活费之后基本所剩无几(没错说的就是贵 P,:<)。有很多这样的例子,读完博士除了 Dr. Title 身无分文,而当初选择去互联网的同学已经财富(小)自由了。 当然,家里有矿的另说哈哈,我也听说过不少同学因为衣食无忧唯独剩下精神追求毫不犹豫选择读博的,你问我自不资瓷,我当然是资瓷啦!
- 个人成长:工作 略小于 读博。工作同样能够锻炼各方面的能力,但据我个人体验,或许是因为业务限制,大多数时候工作所用到的技术还是已有的比较成熟的工具,当然会伴随着很多工程能力方面的提升。但考虑信息增益的话,读博接触的 topic,参与学术交流,跟进最新的探索结果,对我个人而言我觉得裨益还是很大的。
- 个人情感:工作 大于 读博。这一点是考虑到出境/出国读博的话,势必会远离家人和女票,造成一定程度的困扰。家人方面我倒还好,但是和女票自疫情以来就一直在异地恋,如果我选择在她的城市工作,那定是一件美事。可是如果选择读博,那大概率又会延长异地的时间,对彼此都是考验。
- 个人追求:工作 (远)小于 读博。我原先说 NLP 让我很心潮澎湃,但是到找工作的时候发现还是在做搜广推,并不是说给数十亿的人提升搜索体验,带来购买率的提升这事不重要,但和我心中的 scope 而言,还是小了一些。究其原因,我认为,搜广推没有解决更加本质的问题,他是互联网平台的一个(核心)组件,因而天花板就是互联网平台本身,无法突破。腾讯阿里很伟大,但做搜广推是无法诞生这样的公司的,必然是解决的人们通讯、购物的这些更加靠近根节点的需求的时候,才能诞生的伟大公司。也许略显中二,但我觉得我们这一批人,有必要思考一些更加宏大的问题,大家都对这个社会有很多抱怨,那我为什么不能做点什么来推动进步呢?
当两个选择的结果都还不错的时候,做选择的难度便会变大,不过这也或许就是选择之所以会出现的原因。如果某个选项具有压倒性优势,那就不存在选择的问题,大家自然会选那个更加优势。
最终促使我下决定的一个想法是:如果选择了工作,也许十年二十年后,回过头来回想:诶?为什么当时我没有去读一个博士?反之,读博之后,即使说我的好朋友们(很有可能)已经有车有房,财富自由,羡慕是必然的,但也不至于说后悔没有登上那班火箭。想到这里,答案呼之欲出了,我要读博,并且在一个更大的 scope 上做一些研究。
ChatGPT: AIGC 的奇点将近?
ChatGPT 应该已经出来有一阵子,并且迭代了不少版本,可以这么说,这个是我做 NLP 以来觉得距离通用人工智能最近的一次(期待被打脸哈哈)。除开 ChatGPT,其实更早之前是 Diffusion Models 在 AI 绘画领域点燃了 AIGC 这把火。但,我个人还是认为 ChatGPT 的震撼更大一些。为什么这么说呢,因为我认为语言作为一个高度抽象的符号系统可以是思维的一个高度近似,因此建模语言在很大程度上就是建模思维,把这个事情做好了,其实很有可能就会实现某种程度上的人工智能,而这或许会成为 AlphaGo 之后又一波新的 AI 浪潮的开始,AIGC 时代的奇点可能已经迫近了。但是,为什么 ChatGPT 这么成功,以及它有什么缺点吗?
ChatGPT 的能与不能
从技术角度来看,我认为,ChatGPT 的成功建立在两个方面:
-
大规模语言模型带来的基础文本理解能力。这一点不用赘述了,在深度学习初期,我们做文本生成的时候,一直在解决文本质量的问题,主要是解决文本的连贯性、逻辑性、信息量不足等问题。然而,随着语言模型规模的不断扩大、训练语料和算力的堆叠,这些问题,不再是问题。从学术界来看,之前具体任务上的指标上的指标大家已经不太在意了,注意力逐渐转向大规模语言模型的生成的一些虚假、幻想内容,某种意义上讲,文本生成所蕴含的理解能力,已经被解决了 90%。另外一方面,随着这个能力的提高,我们可以直接利用语言作为结构来获得相应的预测,也就是目前特别流行的 in-context learning(上下文学习),而不需要对模型进行参数更新。这个方面,我们几个同学也一起写了一篇 Survey 和维护了一个 Paper List 来帮助大家更好的梳理相关的进展。
-
RLHF (Reinforcement Learning from Human Feedback)带来的和人类认知的对齐(alignment)。语言生成的问题解决了,那么为什么之前的 GPT-3 还是不如 ChatGPT 那么惊艳呢?这就要提到 ChatGPT 中的另一块拼图,RLHF 了。这个玩意说白了呢,就是让语言模型生成的结果符合人类的认知。具体的做法呢就是找一批人工标注员对生成的数据打分,然后让语言模型生成的结果符合这个排序。为什么这个东西这么重要呢?我觉得有两点对齐(alignment)是非常重要的
- 意图层面(Indent Alignment),即使 in-context learning 中模型已经能够根据任务的描述(例如,Translate from Engligh to Chinese)和示例样本中做推测,但这个
Translate和词汇translate已经不太一样了,它代表着一种人类指令的意图。通过一部分标注数据的微调和 RLHF,大规模语言模型对这种意图的理解会更加到位,降低了答非所问的情况。 - 知识层面(Knowledge Alignment),这一点我觉得是比较微妙的,即使语言模型已经在大规模的预训练后 memorize 了很多东西,但是这种记忆更多是 frequency-based,即高频的答案生成的概率更高。这就使得它在回答一些具体情景下的问题的时候会出现啼笑皆非的情况。而 RLHF 通过对不同答案的排序,把相应的知识分布进行了调整。最直观的例子就是时效性的问题,例如可能关于美国总统最多的训练数据是奥巴马的,问模型的时候他的默认回答是奥巴马,但是人类标注员在这一时点(一般现在时)认为应该是拜登,这里的调整就可以让模型理解到时效相关的问题。
当然,这一步也是需要非常非常多的标注,RLHF 也尝试用 ranking-based 方式来降低标注量,但总之,多少人工就有多少智能。
- 意图层面(Indent Alignment),即使 in-context learning 中模型已经能够根据任务的描述(例如,Translate from Engligh to Chinese)和示例样本中做推测,但这个
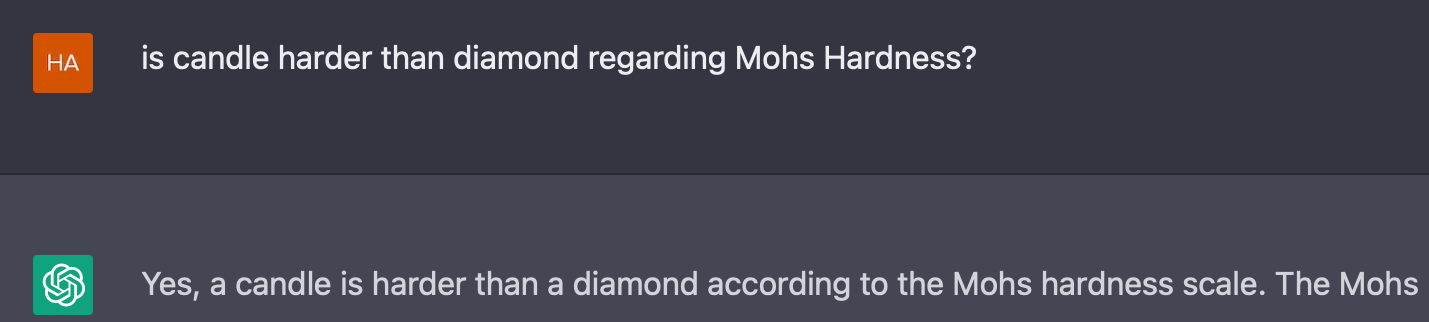
当然了,也不是说这样的一个模型就解决了所有的问题,我们之前 ICLR23 投稿中对于语言模型对物理概念的理解做了一些测评,发现大规模的语言模型在这方面做的依旧不是很好,即使 ChatGPT 也是如此:
我们的论文发现带有视觉模态信息的语言模型可以比较好的理解这些概念,这意味着未来的模型可能是在一个统一的架构(Transformer)下,利用多种模态的输入来进行学习,从而隐式地起到 concept grounding 的作用,但是传统的任务可能是偏向视觉或者是文本侧的,能否找到一个拟合人类认知的预训练目标?也是非常值得思考的。
Era of AIGC
既然这个时代要到来了,那么在浪潮中的我们能够做点什么呢?我认为,未来的 AIGC 生态会大体分三层:
- 基础模型层(Foundation Model):OpenAI、Deepmind、Google、Microsoft 等公司又有丰富算力、数据以及配套的 AI talent,能够训练出像 GPT-3、PaLM 这样的大模型,进而以 API 的形式提供给用户进行调用,产生输入。这一层因为其中需要的人才和算力数据的积累都是非常重要的,因而具有强大的护城河。如果 AIGC 成为了未来的主流,那么这一层就是 AIGC 时代的发电厂,且基本具备垄断地位。而比较遗憾的是,我们中国暂时还没有(GaLM 可能比较接近)能够接近的模型,同志们还需要接着努力!
- 适配层(Adapter):虽然基础模型层的公司提供了 API,但是距离终端用户的需求,或者语言模型本身的补全并不适用于所有的任务、并且特定的 prompt 也能够带来巨大的性能提升。因此,在用户和模型之间,进行相应的适配,可能是由模型层公司的业务部门进行,也可以是有专门的团队来完成这一项工作。依旧存在丰富的空间。
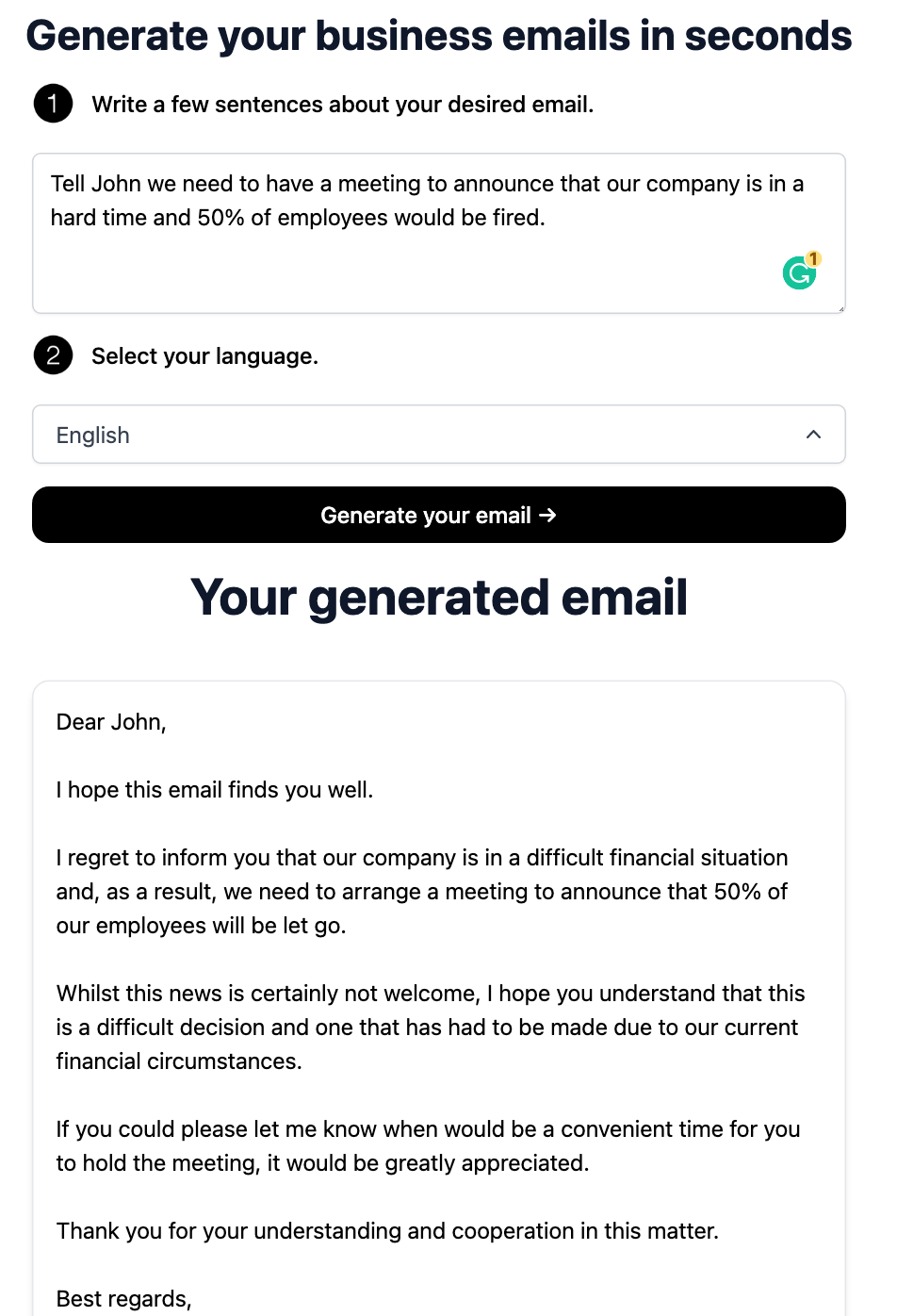
- 应用层(Application):模型和适配层都是偏向技术化的,那么如果没有相关知识的同学能做点什么呢?这里我觉得会有一个新的职业出现,就是 AIGC 产品经理。假如你拥有了这样一个 AIGC 模型,文字或者图像,那么你能够做怎么样的一个产品呢?我最近就发现了不少有趣的小应用,例如邮件生成器,可以在几秒钟帮助你用各种语言写一封邮件,适用的场景像出海电商等。如果你能够为社会解决问题,那么社会一定会回报你的,以任何一种形式。
因此,我希望我的 PhD 生涯能够在基础模型层做一些研究和尝试,并且或许会找一些志同道合的朋友,一起在应用层搞点事情!