
EMNLP21 和 Rebuttal 攻略
这次 EMNLP 很幸运的中了 4 篇文章,有两篇的得分其实挺 negative,最后还是靠着 rebuttal 掰成了 Findings,也算是达到期望。这篇 Blog 就给大家分享一下这四篇工作,毕竟这是一个酒香还怕巷子深的年代(当然,ResNet 这种茅台级别的工作不用PR也是会迟早被家喻户晓的哈哈),以及一些 rebuttal 的感悟。
Text Autoaugment
TAA是关于文本自动增强的策略的一个工作。一作 Andy 哥,也是著名对抗攻击 baseline PWWS 的作者。文章的核心是想要解决 edition-based 数据增强方案的两个问题:(1) DA 对于一些超参数的设置非常敏感,比如删词的比例,造成性能很大的波动;(2): 很多的 edition 操作是拍脑袋出来的,有些是增广操作非常单一,限制了增广数据集的多样性,因此也进一步限制了数据增广的效果。
为此,我们提出将数据增强操作组合成一个 policy,这个 policy 包含了对采取某种数据增广操作的概率,数据增强的 edit type 以及对应的超参(例如删词操作的比例)。并且引入 AutoML 中的 SMBO 来对这个 policy 进行优化。优化的核心思路类似 Meta-Learning,先在训练集上进行 policy 训练,然后在验证集上验证效果,再拿着验证集上的效果作为 feedback 来更新 policy 的参数。
实验部分,我们在 low-resource 以及 class-imbalance 的设定下进行了实验,相比于之前的一些方案能够取得统计上显著的提升。并且还做了一些有趣的分析,例如在小规模训练集上学习的 policy 迁移到大规模训练集上也有比较好的效果,同时不同数据集上学习出的 policy 的迁移性能也有很有趣的模式。具体的细节,大家可以参考我们的 Paper。
在中稿之后,Andy 也带着组里的师弟对代码做了比较多的改动,以适配目前大家用的比较多的 transformers 框架,并且可以通过一两行代码进行配置,可以关注 TAA 的 Repo。
回顾这篇文章的中稿过程,其实还是挺波折的。这边也可以给大家分享一下 TAA 的几次大的改动。(1)最早的一版 readability 存在比较大的问题,因为对问题的建模有一些复杂,带来理解上的难度,几个作者反复讨论多次之后才找到一个比较好的折中,能够把方法讲清楚的同时也让 reader 能够看懂。(2)前几次被拒的时候 reviewer 批评实验不够 convincing。解决的方法就是,我一直反复强调的,就是在条件允许的情况下,特别是对于一些小数据集,假设检验尽可能做。我作为审稿人看到标准差有5个点的情况下带来 5-6 个点的提升,在没有假设检验的情况下我是无法被说服提升的明显的。补充了假设检验以及后续的一些实验,EMNLP 的审稿人认为我们的实验非常 solid(3)除了性能以外,对方法本身的分析是画龙点睛的,最早的版本只有对性能的分析,总会让人感觉审美疲劳,我们后来额外添加了增广数据的多样性分析以及迁移性能的分析,充实文章内容的同时也更全面地展现了 TAA 框架的优点。
Dynamic KD
DynamicKD 则是我们和 Wechat AI 合作的一篇论文。我们注意到目前预训练模型知识蒸馏的 common practice 会把 teacher model / training data / training objective 提前固定好,而没有考虑到 student 模型在蒸馏过程中能力不断变强的这一事实。从这一点出发,我们提出了 Dynamic Knowledge Distillation 这样一个框架,来探究根据学生模型的能力动态的调整三个方面所带来的性能和效率上的收益:
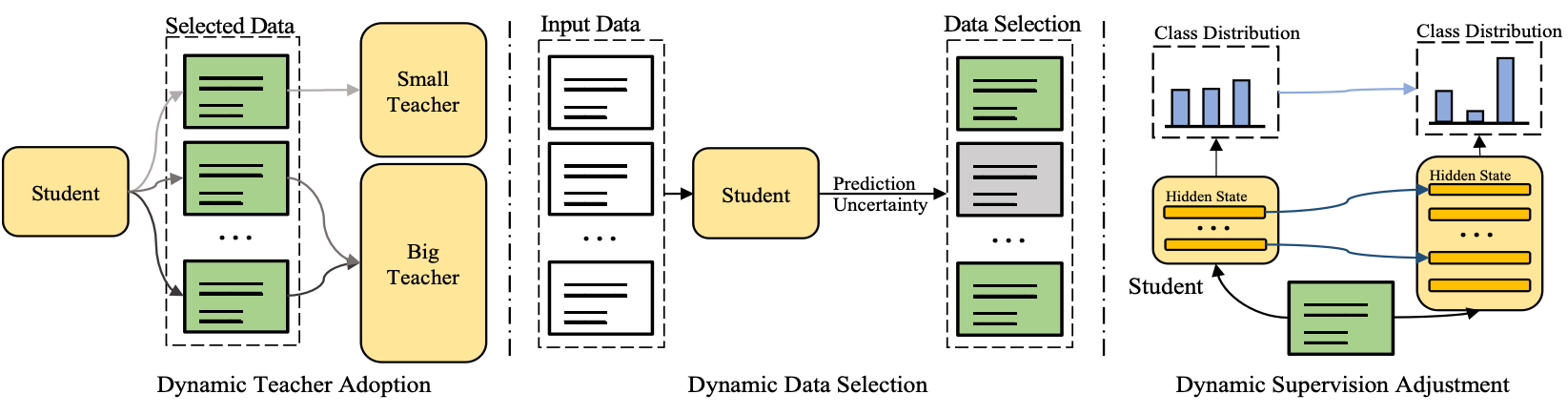
核心的方案也很简单,就是根据学生模型的预测结果的不确定性,不确定性高则意味着学生模型对于当前样本的自信程度较低,则相应地对这三个方面进行挑选即可。下面就简单介绍一下我们探索的一些发现。
Dynamic Teacher Adoption
首先是教师模型的 size 选择方面,我们的实验发现model size 更大效果更好的 teacher 预训练模型不一定能够蒸馏出效果更好的学生模型,因为当学生模型和教师模型的容量差距超过一定阈值的时候,学生模型很难去拟合教师模型的输出,造成蒸馏效果的下降。这一点在 CV 之中之前也有人发现了这一点,我们在 PLMs 上也验证了这样一个现象。之前 CV 的解决方案是引入 Teacher Assistant,即一个中等大小的模型进行过渡以降低教师模型太大所带来的影响,而我们的策略则是:当学生模型对某个样本预测非常自信的时候,则可以更多地依赖较大教师模型的信号;反之,则更多地依赖小教师模型。关于这一点,在 oral 的时候被问到了一个挺关键的问题:模型大小的差距是在 KD 一开始就被确定了的,也即,能力差距实际上是固定的。这一点实际上在我们讨论的时候就注意到了这一点,我们的看法是,模型能力确实只和 size 有关,但同样 size 的模型,在其训练程度不同的时候,能力也有差距。所以当学生模型性能较强时去 query 大的教师模型,能够缓解之前提到的拟合能力不足的问题,进而带来效果上的提升。
Dynamic Data Selection
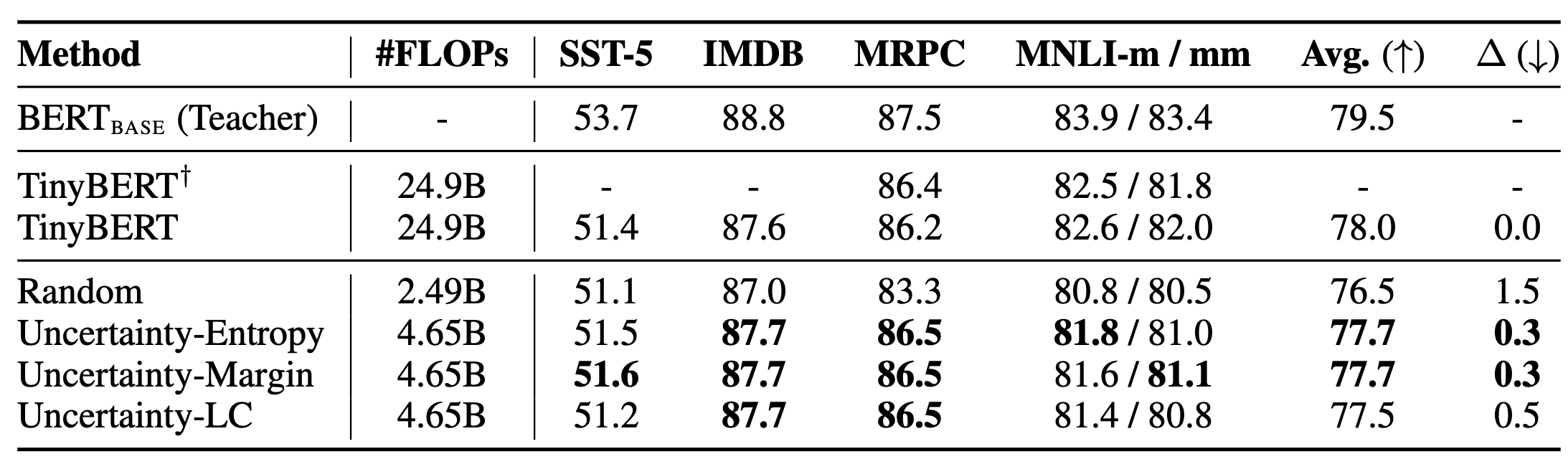
第二个我们探究的方面是动态的数据选择方面,期待找到对于学生模型更加有利的训练数据。这背后的一个事实是,TinyBERT 用了数据增广操作进行知识蒸馏取得了很好的效果,但也带来了巨大的教师模型侧的开销,有没有可能以更加经济的方式达到同样的效果呢。我们的实验发现,借用 active learning 里的一些简单的基于 uncertainty 的策略,每次挑选 batch 内部最困难的 10% 的样本,就可以达到非常接近的效果:
Dynamic Objective Adjustment
最后一个则是目标函数,之前的 setting 一般是提出一个额外的 loss objective,比如 BERT-PKD 的隐状态的 MSE loss ,然后搜索出对应目标函数的权重 $\lambda_{PKD}$并且保持训练中超参数不变。同样的,我们好奇的是,如果动态的调整不同目标之间的比例,是否对最后的效果有所提升?我们在 BERT-PKD 和 KL loss 上进行了验证,发现在模型不确定的时候更多地依赖隐层对齐的目标,以及在模型确定的时候拟合输出概率分布的 KL-divergence 能提升模型蒸馏的效果。
Summary and Furture Directions
总的来说,这篇文章并不是一篇方法性的文章,而是体现了我们对目前 KD 框架一个新维度的拓展,即考虑学生模型能力的 KD 框架,以期望获得更好的效率和性能。未来同样有很多方向值得进一步探索,比如多 teacher 情况下的异构的问题,以及目标函数之间的 correlation,都很值得进一步的挖掘。
CascadeBERT & FormBERT
这两篇都是 Findings,一长一短,就放在一起简单介绍一下。
CascadeBERT 是一篇关注于预训练模型早退(Early Exiting)机制用于推理加速的文章,关于早退,上一篇 blog 尝试做了一个简单的 survey。文章、首先对之前 Early Exiting 方法在高加速比的需求下效果不好的原因进行了分析,结论是浅层的表示信息不足以及中间层的分类器退出决策不准确所造成的。因此后续我们提出把一大一小两个完整的 BERT 拼接在一起,做级联(Cascade)并且对小模型的输出的概率分布进行校准,使得其退出决策更加可靠,因而在高加速比的场景下能够取得更好的效果。这边展开一些我关于早退工作的看法。首先,目前大家测试的时候计算加速比的方法不一,而这一点,Xiangyang Liu & Tianxiang Sun 最近做了一个 ELUE benchmark,提供了一个比较好的基准平台;此外,他们尝试在预训练过程中加入早退的目标函数得到了 ElasticBERT,ElasticBERT 所解决的问题也和 CascadeBERT 类似,CascadeBERT 是利用 google 预训练好的模型进行级联,而 ElasticBERT 则是通过预训练来解决了表示不充分的问题,并且更加贴近 early exiting 的 weight sharing 的模式,效果因此也非常的好。另外,效果很好的 FastBERT 主要得益于其更加复杂的中间层分类器,以及在这之上的自蒸馏目标函数,解决了分类器退出不准确的问题。
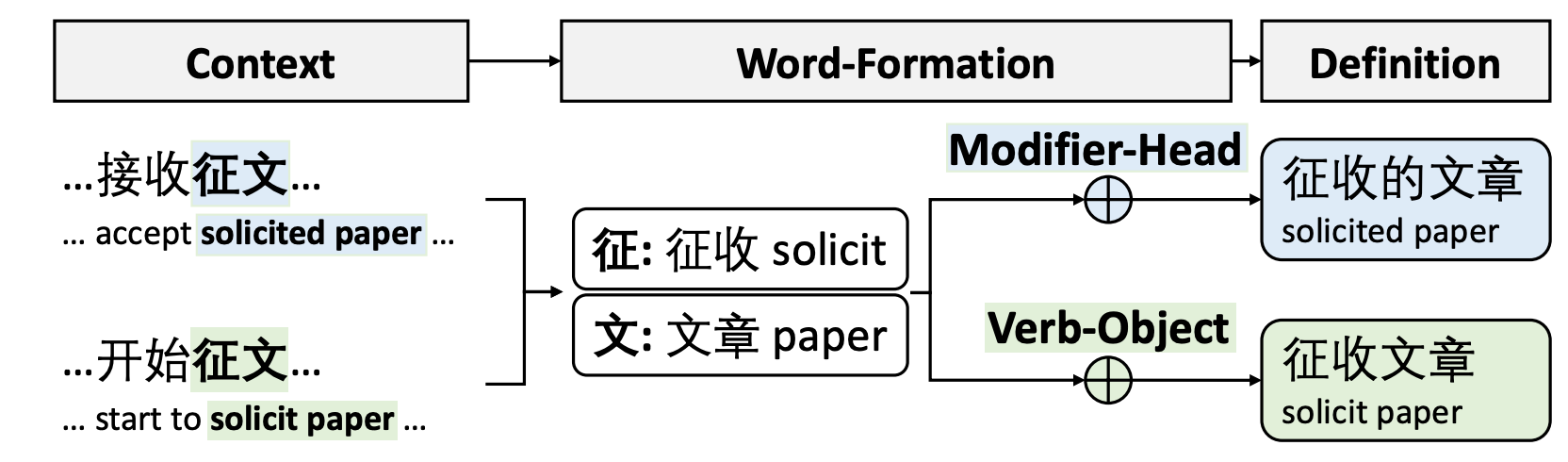
FormBERT 是我和 Hua Zheng 师姐合作的一篇论文。idea 起源于之前我们合作的 NAACL 论文,那篇 NAACL 尝试利用构词信息(Word Formation)来辅助词义生成,我们很自然地就想到这个思路也可以扩展到词义消歧上。具体来说,“征文”中的“征”如果是动词,那么就是一个“Verb-Object”的构词,则对应的“征文”对应的是一个动作;反过来,如果“征”是个定语来修饰“文”,则对应的“征文”就是一个名词,指的是“征收的文章”:
基于此,我们首先构建了带有构词信息的数据集,并且尝试在 WSD 中加入这样的信息,并且引入了一个构词预测模块,来降低推理阶段对这种外部信息的意外。实验发现能够利用构词信息确实能够带来一定的增益。这篇文章的思路本身是挺直接的,但是对于中文构词信息的利用之前鲜有人尝试,Hua Zheng 师姐一系列的工作一直在挖掘这点,我觉得很成体系并且是对中文信息处理很有益处的。数据集因为版权问题暂时还不能 release 出来,应该在不久的将来就能够公布。
Rebuttal
我原先对于 Rebuttal 的认知是一个鸡肋定位的东西,因为审稿人基本不太会看 Rebuttal,因而改分这种事情就变得非常随缘,但是不 rebuttal 又很气,因为有些审稿人实在是太粗心,所以还得老老实实 rebuttal。但是最近几次 rebuttal 都很 lucky 的逆天改命,让我对 rebuttal 又重新燃起了希望。并且最近 Guangxiang 给我们分享了一个 rebuttal 攻略,他亲测在 NeurIPS 上提了 2 分。攻略来自一个 OSU 的团队的 blog,里边有很多 TIPS,这边摘取一些我认为比较核心的分享给大家。
Audience & Goal
首先,搞清楚 rebuttal 的受众和目标很重要,而 rebuttal 的受众其实就两类人:
(1) reviewers,但因为审稿的随机性,审稿人对于你 Paper 了解程度的方差是很大的,因此一些比较难以 get 的东西他们扫一眼过去是看不到的,并且当他们看 rebuttal 的时候,他大概率不记得很多的细节;
(2) AC,对于你的 paper 他是更加不了解的,我们对他们最大程度的假定就是他会读 reviews & rebuttal。
搞清楚受众之后,我们的目标也对应的分成两类:
(1) 对于审稿人,澄清他们的疑惑,回答问题,修正他们的误解,并且回击错误的审稿意见,整合他们的反馈来提升工作的价值;
(2) 对于AC:令他们相信,你的工作做的很好,让他明白 reviewer 的关心的问题在 rebuttal 中很好的解决了,同时,尝试着帮他写一个 meta-review 来提炼文章的亮点,引导他做出决定
这里的 (2) 实际上是我之前一直容易忽略的一个视角,也就是说 rebuttal 是给 AC 看的,搞清楚这一点之后,我们就可以从一个更高的视角来审视 rebuttal。一个合格的 rebuttal,应该能让一个中立的第三方在只看 review 和 rebuttal 的时候,做出相应的决策。
TIPS
下面摘录一些重要的 TIPS:
- Start positive,第一印象很重要,在 review summary 中一定要多一些正面的表述,不然 AC 上来一看都是 negative 那就很容易有先入为主的负面印象,进而造成之后他的决策不利于你的paper;
- 分清主次问题:对于重要的问题,能够被清楚的回答的问题,将它们的顺序往前往。不需要 care 审稿人是否在意顺序的对应,因为他们大概率忘了自己文了什么(x
- 回答问题背后的问题:有些时候审稿人问的一个问题 A,其实并不是想问问题 A,而是想问问题 B,这个时候你得猜出他想问 B 并且回答 B。这个还挺难的,所以得仔细推敲。
- 保持对话的氛围:Rebuttal 并不是让大家吵架,而更多的是一个 discuss 的过程,所以行文的格式上如果有一种你方问罢我解答的对话感觉,就可以让人身心愉悦,进而增加中稿稿率;
- 适当强调,明确的回答/实验结果可以适当 highlight,不然容易 catch 不到终点;
- 用事实说话,即使不能增加结果,若是已有的结果能够明确的回应 reviewer 的关切,那么直接摆证据是最 convincing 的。
这些策略给我独立写 rebuttal 的时候提供了很大的帮助,并且我在 AAAI rebuttal 的过程中也应用了相应的策略,虽然不知道结果如何,这个攻略把 rebuttal 这事很好的系统化了,可以说有攻略在手,rebuttal 不慌。
祝我自己以及大家好运 :) !