
GAN in NLP Notes
最近在感兴趣的一个方向是文本生成,读了以 SeqGAN 为代表的一系列通过 RL 手段来做生成的文章,做一下简单的梳理。
SeqGAN
算的上是开山之作,具体的解读可以看我之前的一篇文章 SeqGAN – GAN + RL + NLP,其通过引入强化学习中的 Policy Gradient 来解决因为离散 token 生成前采样动作造成的不可微。后面的文章也都是基于这个框架来进行深一步地探索。SeqGAN 在 Oracle 和古诗生成任务上做了测试,回过头来看,效果只能说一般。但其开创性的将文本生成看做序列决策问题, 并且将 RL 和 GAN 进行了有机的结合,令人佩服。
LeakGAN
LeakGAN 是交大继 SeqGAN 之后的又一作品,其旨在解决 SeqGAN 中出现的一个问题:一方面,是 Discriminator 提供给 Generator 的 reward 需要等句子完成之后才能被计算(即使用 Monte Carlo 来计算,也只是一种近似的模拟),对于每一步的 token 生成不能得到及时的反馈;另一方面,是 Reward 本身只是一个 Scalar,并不能携带太多的信息。何况对于文本这种结构复杂,同样的意思不同的说法都是可以的,那么数值所包含的指导信号比较弱。这一点我在和学长的交流之中以及自身实验体会也有所感受,GAN 的训练很多时候 Discriminator 的作用不大, Generator 生成文本质量的提高更多是靠 Generator 自学。
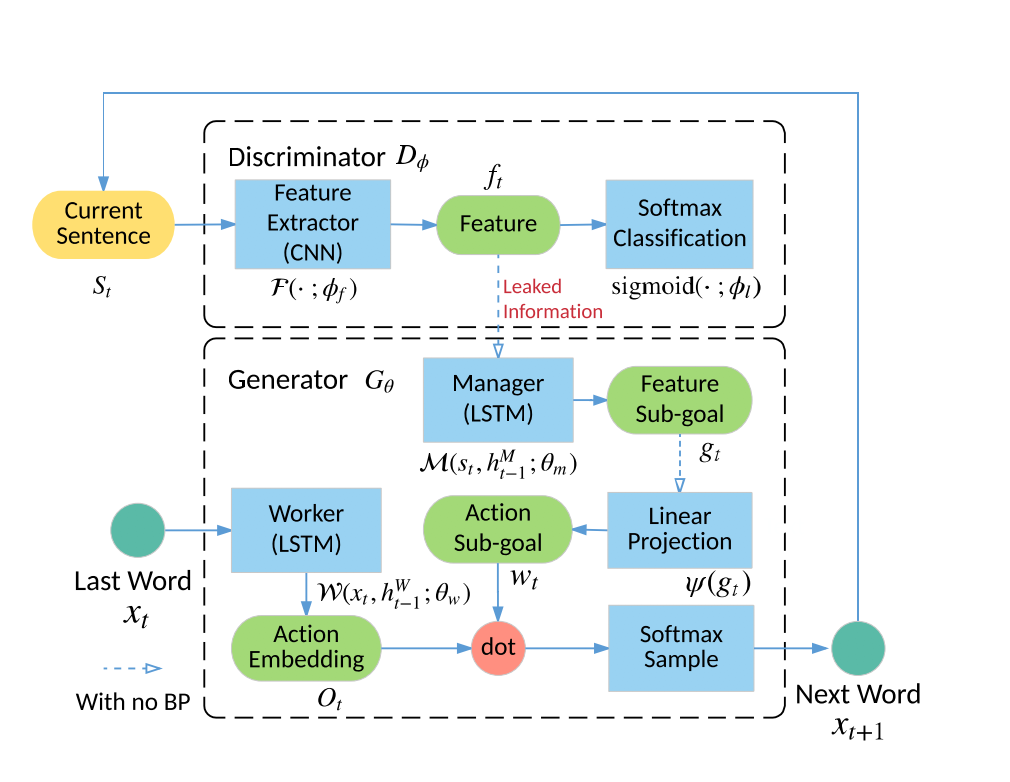
对于信息不足,就让 Discriminator 向 Generator “泄露”一些消息,也就是把作为 Discriminator 的 CNN 最后一层的 Feature Vector 交给 Generator,让这个 Feature Vector 携带大量的信息来指导 Generator 更好的生成。
同时,语义结构的复杂也促使作者使用一个具有层次的生成器,因此在生成器端使用了 Manager 和 Worker 两个模块,分别用于解析 CNN 提供的 Feature Vector 和具体的 token 生成。
整个模型的架构如下:
RankGAN
RankGAN 认为 Discriminator 的 Binary Classification 对于生成多样、符合现实逻辑的文本是不够的。其通过让 Discriminator 对于一个由 human-written 和 machine-generated 构成 Reference 集中的句子进行排序,来指导 Generator 的生成。借鉴 IR 中的相似度的思想,其首先计算两个句子的 cosine,然后据此给出一个语料集上的排序分:
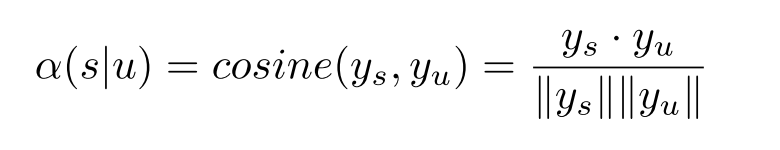
![]()
Softmax 之后得到的依旧是一个类似概率的结果,但这一次不再是真/假的概率,而是衡量句子之间相似程度的概率。最终,和 Reference 中的每个句子的相似概率的数学期望则作为一个 Rank Score 得出,显然,Discriminator 希望真实的句子 Rank Score 越高越好,同时机器生成的 Rank Score 越低越好,因此我们将这个想法套进 GAN 的公式:
![]()
所以,RankGAN 的核心就是用一个 Ranker 来替代 Discriminator,以提供更好地生成句子的评估,进而生帮助 Generator 生成更为真实的句子。
MaskGAN
MaskGAN 的思路则是从生成器端来为生成提供更多的信息,具体的内容也可以参考我的这篇 MaskGAN 学习笔记。Masked Token 给 GAN 提供了额外的信息窗口,通过使用 Seq2Seq 架构来将进行生成,将提供的信息整合进生成过程之中,获取更好的结果。另外一点,Mask GAN 采用了 Actor-Critic 来替换 Policy Gradient,相比 Monte Carlo,能够较好地对 reward function 做一个拟合。
Summary
这四篇文章看下来,可以发现,SeqGAN 提出了这样一个框架之后,主要工作的方向有两个:
- 提高生成文本的质量:我认为,将人类的语言学知识合理地整合进生成的过程,是提高文本生成质量的核心。现有的工作大致是从两个端入手,生成器端通过 Masked Token,比较粗暴地灌进 Generator,Discriminator 端利用句子地相似性,隐式地给判别器端输入语言的知识。二者如果能够做一个结合,可能是一个很有力的架构。
- 短文本 -> 长文本:想要生成长文本,一点是 LeakGAN 中提到的,Discriminator 的指导需要更加 informative;另外一点我觉得和 RNN 的 Long-dependency 的能力也息息相关,LSTM 虽然说能够解决长程依赖的一部分问题,但想要让机器写小说,那就不是 LSTM 能够 handle 的了。LeakGAN 能够把 SeqGAN 的长度由 20 提升到 40左右,但真的到作曲、写小说这种长度,可能需要一个新的框架。
- 解决 Mode Collapse 问题:这个问题可能是前两个问题解决之后,才需要着手考虑的一个问题,即使是我们人类本身,也有着这方面的局限性。比如你的文风事实上就是被你所读过的文章所决定地,虽然说会有一些神来之笔,但我认为那也是早就植根于我们大脑深处的记忆。想要做到真正地创作而不是简单地重复,任重而道远。