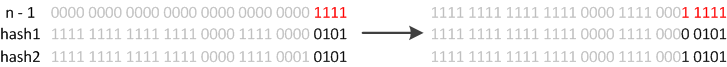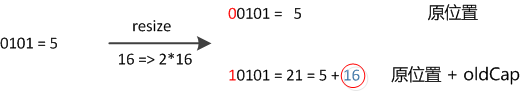数据结构学了哈希查找,于是乎决定学习一下Java中的HashMap。
有两个很重要的问题:
HashMap的哈希算法是怎么样的
Collision是怎么解决的
So,看看Java里HashMap的源码!
Hash table based implementation of the Map interface. This implementation provides all of the optional map operations, and permits null values and the null key . (The HashMapclass is roughly equivalent to Hashtable, except that it is unsynchronized and permits nulls .) This class makes no guarantees as to the order of the map; in particular, it does not guarantee that the order will remain constant over time .
第一段告诉我们几个KeyPoints:
基于Map实现
允许null的值和键
非同步(非线程安全)
不保证有序,顺序也可能随时间变化
HashMap有两个重要的参数: 容量(Capacity)和装载因子(Load factor) (装填的比例)
一般在我们不指定容量的情况下,Java会自动帮我们初始化为容量为16并且装载因子为.75
我们知道,装载因子对于HashMap的性能影响是比较大的,而这个.75是设计者考虑之后得出的。
另外就是当实际的装载因子超过.75这个初始值之后,HashMap会进行一次resize操作,扩容为2倍。
这里值得注意的一点是,HashMap的容量始终为2的幂次 。
哈希算法
第一个问题,key 的哈希算法:
1
2
3
4static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); // 无符号右移
}
可以看到,这里是对key调用了它的hashCode()方法,而一般继承自Object的hashCode()是根据内存地址来计算的,理论上是可以保证不会发生冲突的。
然而这里还把hashCode()计算得到的h 右移16位之后和自身做了一个异或操作,这是为什么呢?
Computes key.hashCode() and spreads (XORs) higher bits of hash to lower. Because the table uses power-of-two masking, sets of hashes that vary only in bits above the current mask will always collide. (Among known examples are sets of Float keys holding consecutive whole numbers in small tables.) So we apply a transform that spreads the impact of higher bits downward. There is a tradeoff between speed, utility, and quality of bit-spreading. Because many common sets of hashes are already reasonably distributed (so don’t benefit from spreading), and because we use trees to handle large sets of collisions in bins , we just XOR some shifted bits in the cheapest possible way to reduce systematic lossage, as well as to incorporate impact of the highest bits that would otherwise never be used in index calculations because of table bounds.
注释告诉我们: 因为实际储存节点的是一个长度为2的幂次的数组,而在计算下标时,使用的是
1i = (n - 1) & hash // n是表的大小
并不是我们常用的%操作,而是&操作,这可能是出于性能方面的考虑。但这样就导致在表比较小的时候,发生碰撞的概率就变大了:比如当n = 16, n -1 = 15(0x1111),这时候生效的只有低4位,碰撞的概率非常大。
因此设计者权衡了速度,作用以及质量之后,用一个比较简便的移位异或操作,这样操作的好处有:
减少因为表长较小而发生的碰撞情况
让高位参与了hash的过程,减少碰撞的概率
开销小
以上就是HashMap的hash函数。
Collision的处理
《数据结构》书上给了3种处理冲突的方法:
开放定址法:主要有线性探测、二次探测、伪随机数三种,主要思想就是就近找到位置放置冲突的key
再哈希法: 用另一个hash再算出一个新的地址
链地址法: 将所有关键字为同义词的记录储存在同一线性链表中
Java采用的是第三种,并且做了一些优化: HashMap会在链表过长(大于或等于常量TREEFY_THRESHOLD)时,将链表转换成红黑树 。这样查找的速度就会从O(n)提升到O(lgn)
还有一点值得注意时,HashMap里的Node类是实现了Map.Entry<>的,也就是,Map会以key-value对的形式保存,而不仅仅只是保存key而不存value ,这样就可以避免不同key算出同一个hashCode而不知道具体是哪一条的情况,而是可以通过key.equals()方法来判断是否是指定的key。
以及可以复习一下Java中equals的相关知识:
相同的对象必须具有相同的hashCode
有相同的hashCode的对象不一定相等,不然就不会发生collision了
所以如果有冲突,通过key.equals(k)去查找对应的entry;若为链表,则在链表中通过key.equals(k)查找,复杂度O(n);若为树,则在树中通过key.equals(k)查找,复杂度O(logn)。
根据以上,推荐用String和Integer这样的不可变对象作为键,避免collision以提高效率。
具体实现
接下来我们就可以来看看get()和put()方法的具体实现:
put()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52public V put(K key, V value) {
// 用hash(key)算出hash值
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 空表则初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 该位置空 命中
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else{ // 发生冲突
Node<K,V> e; K k;
// 同一个key
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode) // 该链为树
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else { // 链表
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 视情况更新value
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 当大小超过load factor*current capacity 需要resize
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
get()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first; // 直接命中 这也是绝大多数发生的情况
if ((e = first.next) != null) { // 未命中 则需要到树/链表中查找
if (first instanceof TreeNode) // 进入树
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do { // 在链表中get
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
get()的实现就比较简单,因为我们通常都会直接命中,如果没有命中,就到树或者链表中去查找。都是通过key.equals()方法来进行key的匹配,而不仅仅只是hashCode的相等 。
resize()
我们在上文之中提到: 当load factor * current capacity > threshold会发生resize,将table扩大一倍,难道又要重新计算一遍hashCode重新摆放吗?来看看它的实现:
Initializes or doubles table size. If null, allocates in accord with initial capacity target held in field threshold. Otherwise, because we are using power-of-two expansion, the elements from each bin must either stay at same index, or move with a power of two offset in the new table.
注释说元素要么待在原来的位置,要么在原位置上移动一个2次幂。
怎么理解呢?
当我们从表长为16拓展到32到的时候,n-1从0x1111 变为 0x11111
而(n-1) & hash 的结果前面的位数是保持不变的,增加的一位不是0(保持原位)就是1(移动一个2次幂,也就是移动一个长度oldCap),看图:
所以新的index会发生如下的变化:
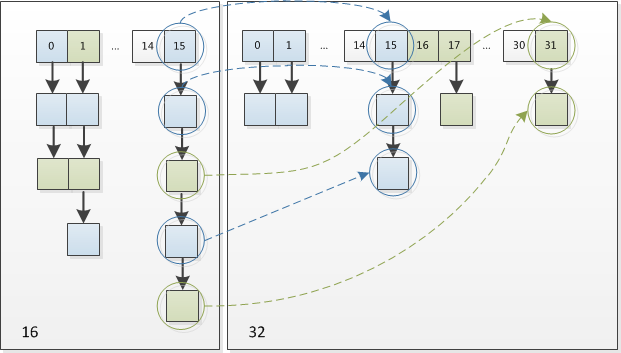
所以,在resize过程中我们不用重新计算一次hash,只要看看增加那一位是0还是1就可以了。以下是一个16扩充到32的resize示意图:
代码的具体实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 超出了最大容量 无法扩容
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 扩容一倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新的threshold
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) { // 移动每个元素
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null; // 清空原位
if (e.next == null) // 直接放置
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode) // 树中节点的移动
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order 保存前驱 以下是对链表中节点的移动 结合示意图理解
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) { // 保持原位的节点
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else { // 原index + oldCap的节点
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 放到新表中的原位置
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 新表中原位置+oldCap
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
总结
HashMap的哈希算法是调用object.hashCode()并且与它的结果右移16位做异或得到的,通过(n-1) & hash来计算下标。
Collision的解决用了链地址法,并且会在长度超过一定值的时候转换成一颗红黑树。
HashMap可以接受为null的键和值,是非同步的。
当load factor * current capacity > threshold时调用resize()方法扩容一倍。
参考资料
Java-HashMap工作原理及实现
HashMap的工作原理