
Python爬虫学习-1
前几天看了Google I/O,主题是”Mobile First to AI First”,然后又去听了一场微软工程师关于Machine Learning,主要是数据分析方面的讲座。很明显的感受到,移动互联网的浪潮正在慢慢退去,而AI、ML浪潮蓄势待发。记得吴军在《浪潮之巅》里讲,能够成为浪潮中的弄潮儿是很幸运的。但是,傻呆呆地在岸上等待,只会被巨浪裹挟,然后被拍死;而只有迎面而上,才能拥抱浪潮。
废话了那么多,大致意思就是:我要学习ML,避免落后。而学习ML,需要大量的数据,数据从哪来?Python爬虫。So,开始!
Python爬虫
爬虫嘛,也不是第一次听说,就是把网页的内容抓取下来,然后进行分析处理。主要会用到的库大概有urllib, requests, BeautifulSoup4等等。然后前天貌似要做教师测评,于是乎就想能不能写个爬虫模拟登陆一下教务系统,然后帮我把测评做了?在HeroHR的帮助下,用urllib实现了查成绩(虽然和评测有点区别),后来听说requests才是“HTTP for Humans”(给人用的HTTP,和Java的手搓Socket比起来,确实啊),然后就又用requests库写了一个。
准备工作
登陆的过程大致分两步:
1. POST账号密码
2. 服务器交给浏览器一个Cookie,以辨别身份
当然有些时候很多网站会设置一些token来保证安全或者防止抓取,就需要我们从网页源代码中入手来观察。
首先,我们就打开教务处的网站,然后登陆一下,并且通过Chrome的检查选项来观察在登陆过程中我们给服务器POST了哪些数据
http://ids.xidian.edu.cn/authserver/login?service=http%3A%2F%2Fjwxt.xidian.edu.cn%2Fcaslogin.jsp
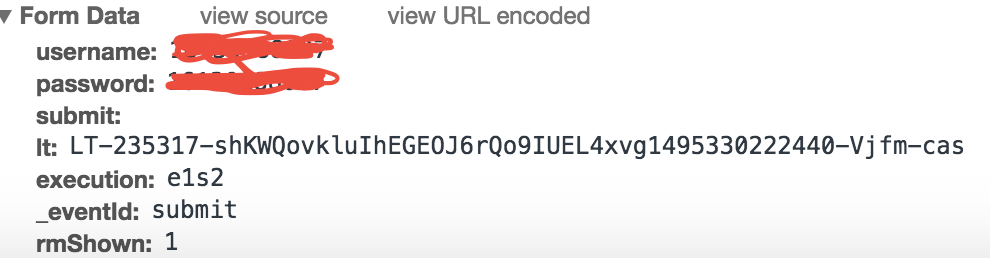
我们看到POST的表单中有username, password, 以及一串很长的奇怪的字符串,目测这个就是网页来保证安全的token了,于是乎我们打开网页源代码,来查找一下这段“奇怪的字符串”。

哈哈哈,果不其然,它就藏在这个网页里。还有一些其他的参数例如_eventId, rmShown, execution,登陆几次之后就发现,前两个的值是固定的,而后面一个似乎是登陆的次数,第一次登陆的话他的值都是“e1s1”。那么我们只要先爬出这个网页,然后用正则匹配出lt,再作为post的表单数据POST给服务器就可以了。
模拟登陆
准备工作完成,接下来,就可以来写代码啦。
|
|
这里我们用到了一个opener对象,看官方文档:
class urllib.request.build_opener([handler, …])
Return an
OpenerDirectorinstance, which chains the handlers in the order given.
还是不知道他在说什么,不过既然是一个OpenerDirector实例,那就再去看看它是什么:
class urllib.request.OpenerDirector
The
OpenerDirectorclass opens URLs viaBaseHandlers chained together. It manages the chaining of handlers, and recovery from errors.class urllib.request.BaseHandler
This is the base class for all registered handlers — and handles only the simple mechanics of registration.
大致明白了,就是用带有一些Handler的url打开方式,而这里我们实际上穿进去的参数是HTTPCookieProcessor,用于处理服务器交给我们的Cookie。
还有一点需要注意下,因为网页的内容是流式的,我们请求一次,服务器发送一次,所以如果我们对一个response读取两次,第二次就读不到任何东西 (掉进这个坑里,然后不知道为什么,幸好全栈的HeroHR及时提醒了我)。
到这里,我们的模拟登陆就完成了。
查询成绩
登陆进去之后,在教务系统里找到查成绩的连接:
[2016-2017学年第一学期(两学期) ]
后面那一坨是什么鬼???
HeroHR和我一开始觉得可能是学号,于是对着一个一个的数,因为比较长,数了两遍,发现位数对不上,然后我想可能是随机数?机智的他发现了括号,于是猜测是不是学期,然后又数了一遍,对上了!!!转成gbk,Perfect!!
Keep Going!
|
|
打印出来的成绩的结果是这样的:
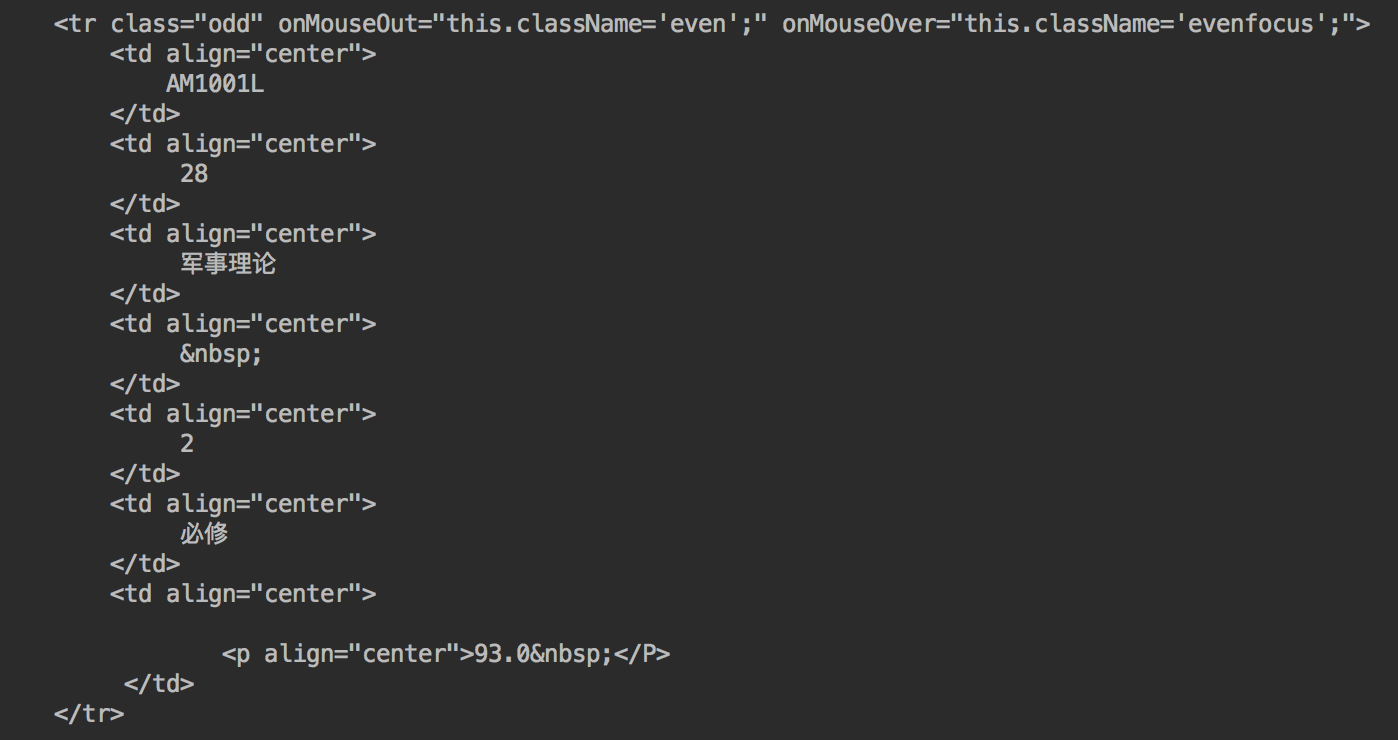
这要是用正则来匹配,就很麻烦也费时间,于是BeautifulSoup4出场了。
Beautiful Soup is a Python library for pulling data out of HTML and XML files. It works with your favorite parser to provide idiomatic ways of navigating, searching, and modifying the parse tree. It commonly saves programmers hours or days of work.
它的工作原理(个人猜测)就是以标签为节点来遍历整个HTML的文档(因为HTML和XML是标签化的语言),然后建立起一颗树,那么我们就可以迅速的遍历这颗树来得到我们需要的信息。
这里我们可以看到,课程信息在<tr>这个标签里,而成绩在<p>里面。所以我们只要提取这些标签,拿到他们的内容就可以了。
|
|
tag是bs的一个类,他可能包括他的子节点(tag)和一个叶子节点(没有子tag的节点,type为NavigationString)
我们可以通过tag.contents获取内容列表,经过对内容的分析,我发现tag.content[5]就是课程的名字,所以用一个list存起来。
|
|
于是,大功告成!
输出的结果:
军事理论 80.0
军事训练 80.0
大学英语(I) 免修
高级英语(Ⅰ) 80.0
思想道德修养与法律基础 80.0
大学生职业发展 通过
形势与政策(Ⅰ) 80.0
大学体育(I) 80.0
高等数学A(I) 80.0
大学物理(Ⅰ) 80.0
计算机导论(Ⅰ) 通过
计算机导论(Ⅱ) 80.0
新生研讨课 80.0
专业教育(Ⅰ) 通过
计算机系统组装实习 优秀
应用创造学 优秀
(你问我为什么都是80??因为我改了不想给你看啊哈哈哈哈哈)
用requests来实现
用号称HTTP for Humans的requests库实现模拟登陆查成绩,是怎么样的呢?直接上代码!
|
|
除去注释和空格,核心代码只要8行!!!
8行,你写不了Java的一个Hello World,你可以模拟教务系统登录查成绩啊
其中很重要的一个类,Session,是它帮我们做了很多幕后的工作:
Session Objects
The Session object allows you to persist certain parameters across requests. It also persists cookies across all requests made from the Session instance, and will use
urllib3‘s connection pooling. So if you’re making several requests to the same host, the underlying TCP connection will be reused, which can result in a significant performance increase (see HTTP persistent connection).
会话对象,持续的请求,保存Cookie。自动的TCP连接复用。
强爆了,不愧是给人用的!
总结
一直和HeroHR争Java和Python哪个好,其实语言只是工具,没有高低之分,怎么用才是最重要的。
在某些领域比如爬虫、科学计算,Python写起来简单,库多而全面。Java也同样有自己的领域。
爬虫之旅才刚刚开始,机器学习似乎因为数学知识储备还不够,可能得缓一缓,但学爬虫也是为了机器学习做准备啊。
路漫漫其修远兮,吾将上下而求索。