
调参侠的自我修养
昨天刷完了 Andrew Ng 深度学习的第二部分课程
Improving Deep Neural Networks: Hyperparameter tuing, Regularization and Optimization
收获还是非常大的,虽然 Andrew Ng 对一些 tricks 的数学细节一笔带过,但通过画图之类的手段来让我获得了一个很形象的 intuition(直观感受),后面数学的部分也要靠自己再去啃书了。这篇 Blog 主要就是对课程内容的一个梳理。
Pre-processing and Regularization
对应第一周的内容,主要讲解了 Deep Learning 和传统 Machine Learning 一些细节的区别:
- Train / Dev (Cross Validation) / Test Sets 的分割。在 ML 里我们经常会用 6/2/2 这样一个比例,而在大数据量下的 Deep Learning,则一般会选用 98/1/1 甚至是 99.5/0.25/0.25 这样一个比例,尽可能的利用数据,来训练出一个更好的模型。另外需要注意的一点就是保证 Dev Set和 Test Set 这两个集合来自同一数据集,以确保我们能够通过在 Dev Set上的评估能正确反映在 Test Set 的性能。
- Deep Learning 中 Bias 和 Variance。Bias 和 Variance 需要和一个较为客观的指标进行对比,比如识别中的猫和狗,假设人类的正确率为 99.9%,那么如果我们的模型正确率只有 99%,那么这就可以说是 Bias 了。另外,在 ML 中有时需要进行 Bias 和 Variance 的权衡,但 Deep Learning 是可以训练出一个足够好的模型而不用进行这种权衡的。
Andrew Ng 也给出了“Basic Recipe for Deep Learning”:
评估模型:
- High Bias:用更大的模型;训练更久;更换 NN 模型。再次评估模型。
- High Variane:获取更多的数据(数据增强);Regularization。再次评估模型。
Pre-processing
事实上数据预处理的手段很多,课程主要讲解的是 Normalization,归一化,让数据保持相对关系的同时,更具可比较性。归一化的主要目的是让梯度下降收敛的速度更快。
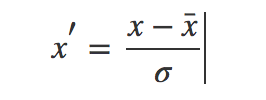
我们让原有数据减去平均值 x拔,再除以方差,得到归一化后的数据 x`。
这里有一个问题就是 Test Set 上的平均值和方差如何计算,是利用训练集上每个 batch 的 Average 和 variance 做一个 EWMA(后面会提)得到,从而保证 Test Set 的预处理和 Train Set 保持一致。
数据预处理真的非常重要,我在 Kaggle 上的 MNIST 识别里仅仅将像素值归一到 [0,1] 区间,就使得模型的准确率上升了接近 1%,亲身体验告诉我,这个 trick 方便而又有效!
Regularization
在 ML 中我们有 L1,L2 级别的 Regularization,深度学习中用的比较多的是 L2。
L2 Regularization 在 BP 过程中体现为在更新 dw 的时候增加了一项 decay 项,所以这使得权重不至于过大,从而使得模型能够防止过拟合。控制 L2 的是一个 Lambda 惩罚系数,是需要根据模型调整的。
还有一种在 DL 中常用的 Regularization 手段就是 Dropout,随机地使一些 hidden unit 的输出值变成 0,从而使得神经网络不会依赖特定的一个 hidden unit 或者说是 feature,而会尽可能的把权重分摊到各个 feature,使得神经网络能够具有更好的泛化能力。这里通过 keep_prob 来控制随机被置为 0 的 hidden unit 的比例,一般取为 0.5。
另外还有一些防止过拟合的手段:
- 数据增强,通过对已有数据的变换、组合得到更多数据,比如图片旋转、翻转、裁剪
- 提前终止训练,通过检测 Train Error 和 Dev Error 的曲线变化来停止训练,防止继续训练是的模型过拟合
Optimization Algorithms
对应第二周的内容,主要讲解了几种主流的梯度下降算法,假设我们数据集总共的样本数为 m。
Batch Gradient Descent
一次在一个 epoch (through the whole data),就是整个数据集(m条数据)上进行梯度下降的计算。在大数据量的深度学习之中这种算法优化的速度不是非常理想,但能够找到最优值。
Stochastic Gradient Descent
一次在一组数据上进行梯度的计算,因为样本较少,无法利用矩阵来加速运算。除此之外,还会引入一些噪音,所以 Cost Function 随着迭代的进行而剧烈震荡下降。这种方法的收敛速度比较快。
Mini-Batch Gradient Descent
这就是前面两种算法的折中,1 < mini-batch size < m,一般会取 64,128,256(一般以填满GPU/CPU 为最佳),这也是目前深度学习中最主流的手段。
Momentum
在介绍 Momentum 之前 Andrew 先介绍了一种处理数据使数据平滑的 trick:Exponentially Weighted Moving Average(EWMA),公式如下:
Vt=β Vt-1 + (1 - β) θt
如果把这个递推公式展开的话,Vt 可以看做是一个前面 1 / (1-β) 个数据的平均值。
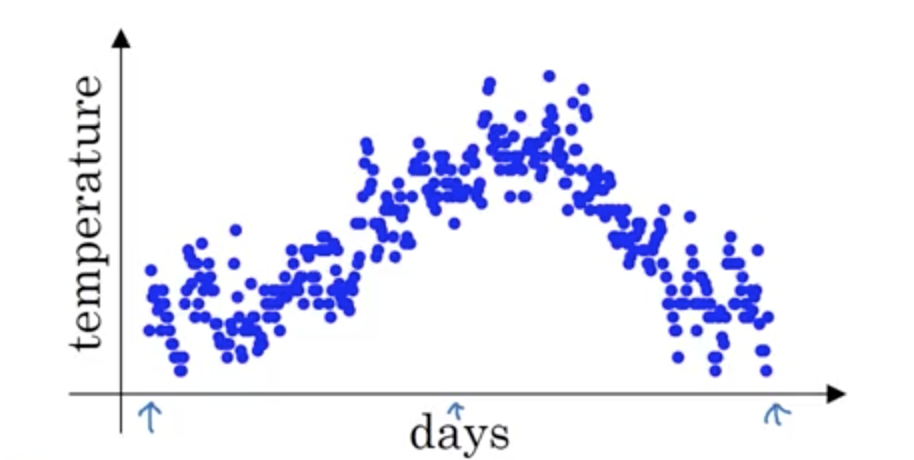
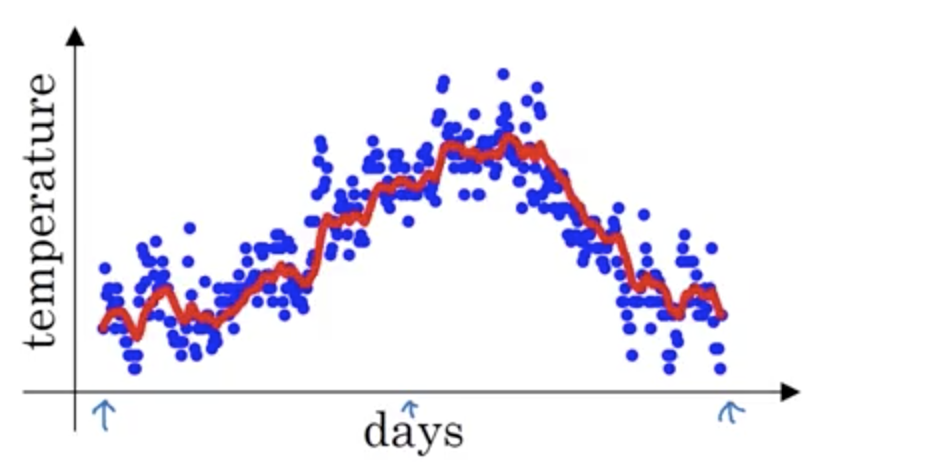
效果如上图所示,用一条红色的曲线来替代蓝色的离散点图,β 越大曲线越平缓,越小震荡越厉害。
在前面几个点的处理效果上会导致平均值较小,使得整体曲线偏向下方,为了修正这部分我们有时会给 Vt 除上一个 (1 - β^t)
然后借鉴这种思想,用在 Gradient Descent 上:
Vdw = β Vdw + (1 - β) dw
Vdb = β Vdb + (1 - β) db
W = W - α Vdw ; b = b - α Vdb

结合上图,蓝色曲线是没有 Momentum 的梯度下降,红色是使用了 Momentum 的梯度下降曲线。从取平均这个角度来理解:纵向的梯度有正有负,平均之后,趋于 0,横向梯度都是同一方向,平均之后正负号不改变。所以我们看到红色曲线更快,更少震荡(意味着陷入局部最优的概率变小)地下降到了全局最优点。β 通常在 0.9 ~ 0.98 这个范围
RMS Prop
Root Mean Square Prop(RMS prop)是另外一种梯度下降算法,和 Momentum 比较类似:
Sdw = β Vdw + (1 - β) dw^2
Sdb = β Vdb + (1 - β) db^2
W = W - α dw / sqrt(Sdw + epsilon) ; b = b - α db/sqrt(Sdb + epsilon)
RMS Prop 的好处在于我们可以用更大的 Learning Rate 而不用担心步子太大扯着蛋。
Adam
Adam 结合了 Momentum和 RMS prop,计算 V 和 S(注意,两个 β 参数不同),以及相应的修正后的 Vcorrect,和 Scorrect,最后在更新权重的时候,用 V 代替 dw。这是现在在大规模深度学习中非常广泛使用的一种算法。
Hyperparameter Tuning
调参侠的自我修养的重点部分:
- Hyperparameter 调整有优先级的考量:
- Learning Rate
- Momentum β, 隐藏层的单元数,mini-batch size
- 隐藏层数量,Learning Rate Decay
- Try random values,don’t use a grid:随机取点调参,而不要按部就班的用格点图。
- 在 log 级别设置范围,由大及小。比如在 0.001~1 调整学习率 ,分成 0.001~0.01、0.01 ~ 0.1、0.1~1 这样三个曲线,在三个区间内随机取点调试。
Batch Normalization
最后一块就是 Batch Normalization,这一部分的思想和前面数据预处理非常类似。
我们在神经网络中如果对第 l 层的输出 z(l)(或者是a(l)) 做一次 Normalization,同样能够使得我们的模型更具泛化的能力。
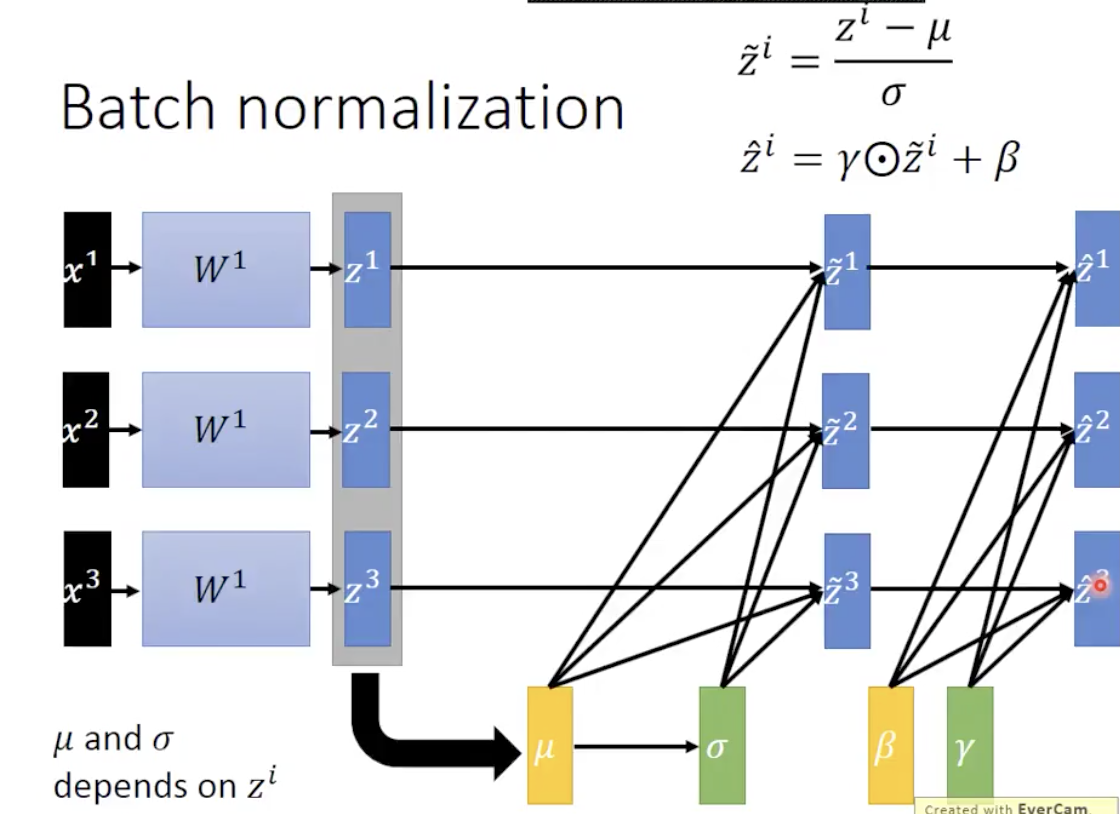
对第 l 层里的每个单元 x(i)进行如上图所示的计算,这里的 γ 和 β 是需要我们去学习的参数。具体的原理有待读 Paper 研究。
这边记录一下 Andrew Ng 认为 Batch Norm as regularization 的观点:
- Batch Norm 对隐藏层之间数据做了 Normalization,因为通过归一化后,使得后面的隐藏层对前面隐藏层数据的变化适应能力更强,通过链式法则可以使得模型对于输入的变化有着更强的适应能力
- Batch Norm 给 z(l) 添加了噪音,使得 a(l) 也有了噪音,更加具有泛化能力
- Batch Norm 带有轻微的一些正则化的功能,但不常作为正则化的手段